

GEN數據新聞獎(Data Journalism Awards, DJA)是由谷歌、騎士基金會(Knight Foundation)和全球編輯網絡(Global Editors Network, GEN)共同設立的數據新聞領域最受關注大獎。今年,評委會共收到來自全球各地將近500多件參賽作品,其中78件作品入圍最終各獎項角逐。評委們將從中選出10個獲獎作品,並於6月18日西班牙巴塞羅那的GEN數據新聞峰會上宣布結果。
今年大會的主評委、谷歌新聞實驗室的數據編輯Simon Rogers說,今年有兩個亮點讓他刮目相看:“不少高質量作品來自數據新聞的後起之秀;全世界正興起一股利用開放數據結合講故事技巧的熱潮。”
“年度調查”(Investigation of the Year)是GEN數據新聞獎的十個獎項之一。今年有17個作品入圍“年度調查”獎,深度君將為大家介紹幾款“心頭好”,跟隨數據記者們一窺這些藏在數字里的秘密。
FT調查:漢能尾盤十分鐘的爆發

有關中國首富李河君和他所創辦的太陽能公司的報道-“漢能尾盤十分鐘的爆發”,是《金融時報》目前為止所做過最有野心的數據驅動的調查,嚴謹的數據分析使其成為金融方面的調查報道典範。
漢能薄膜發電是漢能集團旗下的上市子公司。作為一家中國民營企業,漢能集團主要專註於薄膜太陽能技術。在不到兩年時間裡,漢能薄膜發電市值一路飆升,已經超過了Twitter和電動汽車製造商特斯拉(Tesla),而擁有該公司73%股份的創始人李河君成了中國最富有的億萬富翁。為了分析這隻直到去年還鮮為人知的太陽能小盤股股價飆升的原因,英國《金融時報》梳理了香港最大上市公司的1.4億次單筆交易。
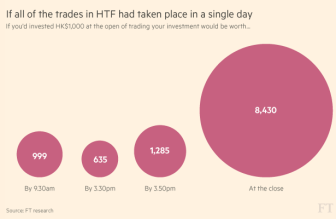
自今年一月,《金融時報》就開始關注漢能集團,他們想搞清楚這個太陽能公司如何在兩年內達到了355億美元市值。今年二月份,金融時報不同團隊的記者們(從數據、交互,到金融、繪圖)跨部門通力合作,用數周時間分析了該上市公司以分鐘計的交易數據,最終發現一個非同尋常的交易模式:從2013年初到今年2月份,這間太陽能公司的股票總在尾盤時分出現飆升,時間大約在收盤前10分鐘。這種暴漲極有可能是這隻股票過去兩年驚人的股票增長背後的動力,並且,《金融時報》的分析也表明,幾乎沒有其它股票在尾盤有如此活躍的表現。
這篇調查報道於2015年3月24日發表後在中英文媒體間引發極大關注和諸多跟進報道,FT的網頁流量也呈螺旋式上升,為報道所製作的音頻節目有至少十萬人收聽,不少讀者留言肯定該報道的嚴謹程度。這個調查讓人們質問誰在操縱股市,以及隨着中國市場擴張、大陸投資者在境外尋求更多機會,香港股市是否得到足夠監控。《金融時報》這次調查精確、公允,並且大量使用圖表推進調查結果,堪稱他們最成功的公共利益報道之一。
英國《金融時報》的分析方法
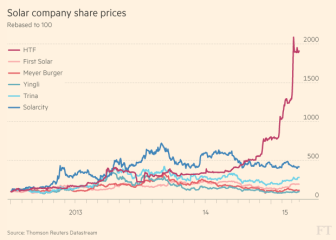
英國《金融時報》分析了漢能薄膜發電從2013年1月2日到2015年2月9日期間在香港股市的每筆交易數據。
英國《金融時報》以10分鐘為單位劃分了這些數據,並跟蹤了每個10分鐘開頭和結尾的交易價格。整套數據共有1.4億個數據節點。漢能薄膜發電的數據是根據每日交易情況編製的,佔了其中逾80萬個數據節點。
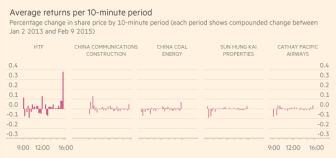
回報則是用兩種不同方法計算的。在第一種方法中,英國《金融時報》計算了交易日中每個10分鐘片段中第一筆交易和最後一筆交易的價格差異。在第二種方法中,英國《金融時報》比較了一個10分鐘片段中的第一筆交易與後一個片段中第一筆交易的價格差異,還比較了一天的開盤價與此前一天的收市價。
基於這些數據,英國《金融時報》計算了這隻股票在上述期間每10分鐘的平均回報和複合回報,也用同樣的方法計算了每月和每日的回報,並與隨機選取的其它幾支香港上市的股票做了比較。在分析過程中,英國《金融時報》使用了SQL數據庫查詢語言及統計編程語言R語言。
WSJ調查:醫保解密
“醫保解密”是美國《華爾街日報》所做的一系列數據驅動的調查報道,內容有關美國信息透明度極低的醫保系統:6000億美金的醫保賬單是如何被花出去的?
這一系列報道最終使得美國政府被迫於2014年4月首次公開了自1979年以來一直保密的重要醫保數據,《華爾街日報》也在數據公開後繼續跟進一系列全面調查,分析和披露醫保體系如何濫用納稅人的錢。
政府得以公開這些信息,主要歸功於《華爾街日報》母公司道瓊斯的勝訴,以及《華爾街日報》記者團隊鍥而不捨的報道和跟進。《華爾街日報》利用這些新公布的數據,勾勒出醫療與貪婪在美國醫保體系中的勾結,美國納稅人每年至少掏出600億美金為偽造的醫保款項買單。
這一系列的報道被稱為“醫療解密”,併產生行業震蕩。比如,其中一篇文章檢視了類似卡氏肺囊蟲肺炎(PCP)等非常見疾病的體檢項目和藥物的昂貴費用,隨後,醫保管理機構-美國醫療保險和醫療補助服務中心(CMS)正式否決了覆蓋更多體檢項目的提案,並考慮下一年中實施改革措施,以控制超額的開銷。另一個重磅調查則找出一些手術收費和利潤明顯比其他人高的醫療供應商,沒過多久,美國聯邦調查局(FBI)便開始立案調查其中一個供應商。
“醫療解密”系列並非簡單呈現所獲得的數據,而是由一個調查記者和數據專家所組成的團隊分析和搞懂這些數字背後的聯繫,並製作了一系列互動圖和表格,條理清晰,有大量細節呈現。
《華爾街日報》花費了大量時間、金錢和記者資源使這一系列調查得以誕生。多年來,美國政府一直拒絕提供醫保賬單的信息。而當美國醫療保險和醫療補助服務中心(CMS)終於在2010年4月公開相關信息時,他們也沒有提供任何針對這些數字的分析。這對華爾街日報的團隊是極大挑戰,他們必須確保調查結果的公平合理和數據分析的準確,避免針對任何具體醫護人員。他們分析了這個數據組中的920萬條記錄,從而在2014年發表這一系列名為“醫療解密”的報道,這組文章向人們揭示了這個原本為老年人和殘障人士所設置的,涉及6000億美元的龐大工程之運作內幕。
《華爾街日報》的分析方法
儲存和分析整套醫保系統數據是個相當複雜的工程,但它卻是這一數據調查運作的基石。
整套數據由兩部分組成:一部分是政府公開的數據表格,總共包含大概1000萬條記錄;另一部分則是政府公開信息前,由《華爾街日報》向CMS花錢申請的數據,多達幾十億條記錄,其中有過去六年多里大量記賬人每一條賬目的細節。
光是查詢後一數據集就要花上幾天時間,寫代碼分析則更是艱巨任務。為了能將數據導入Microsoft SQL數據庫,記者們用C#語言寫程序,把幾百行的表格記錄處理成可以用來返回有意義結果的關係表格。
為了確保工作內容的可重複性,數據記者們通常用R寫代碼來進行分析。他們利用了大量分析工具研究這些數據,包括線性回歸、邏輯回歸、主成分分析、K均值算法和多種期望最大化算法。儘管這些工作並不都能在最終成果中得以呈現,但這一步驟對於記者了解具體調查線索和數據中整體模式之間的相關性是至關重要的。
《華爾街日報》的交互圖表團隊在數據被公開當天也同時發布了一個可供搜索的醫保供應商數據庫。隨後的幾周乃至幾個月時間裡,團隊不斷在該數據庫上添加新的功能和深度,並最終將這個項目叫做“醫保解密:數字背後”。這個交互現在是“醫保解密”系列報道的封面,它呈現了88萬醫保系統中的醫生和供應商的信息,讓任何人都能很容易查到每一地理位置和專業科室中的最大受益人。
該數據庫也添加了每一供應商賬單數據的背景信息,幫助人們理解這900多萬個數據節點中存在的聯繫。這個可做搜索的數據庫是用REST API製作的。查詢請求會通過PHP發送到一個MySQL服務器上,再向瀏覽器返回JSON格式的數據。他們使用了PHP中一個簡單的緩存,避免重複查詢數據庫中的一般查詢指令。瀏覽器的展示使用了HTML,Javascript和PHP。
