
 編者按:《調查報道信息核實手冊》(Verification Handbook for Investigative Reporting)是一本有關網絡搜索和調查技巧的新鮮實用指南,指導人們如何利用UGC(user-generated content, 即用戶生產的內容)和開源信息進行網絡搜索和調查。此手冊由總部設於荷蘭的GIJN成員“歐洲新聞中心”(European Journalism Centre)出版,共有10章,均可免費下載。以下是獲得授權轉載並編譯的該書第5章,由調查記者Giannina Segnini編寫。
編者按:《調查報道信息核實手冊》(Verification Handbook for Investigative Reporting)是一本有關網絡搜索和調查技巧的新鮮實用指南,指導人們如何利用UGC(user-generated content, 即用戶生產的內容)和開源信息進行網絡搜索和調查。此手冊由總部設於荷蘭的GIJN成員“歐洲新聞中心”(European Journalism Centre)出版,共有10章,均可免費下載。以下是獲得授權轉載並編譯的該書第5章,由調查記者Giannina Segnini編寫。
時至今日,記者們接觸信息的渠道之多前所未有。現在世界上每天生成的數據有3 EB之多,相當於7億5千萬張DVD 的容量之和 (1EB = 1024TB = 1048576GB = 1073741824MB),而且這個數字每3年零4個月就能翻一番。今天全球數據產量是以YB來計算的(1YB相當於250萬億張DVD的容量,即1024*1024EB=1048576EB)當數據容量擴充到YB以上,人們就開始討論該用什麼新單位來測量容量了。
數據生產的容量升級,速度提升,讓眾多記者無所適從。他們中很多人還不習慣用大量的數據做研究、寫新聞。但是利用好數據的渴望和迫切,以及目前可用的處理數據技術,不能動搖基本的準確性要求。為了汲取數據的全部價值,我們必須具備區分可疑信息和優質信息的能力,能在干擾信息中發現真正有價值的故事。
我做數據調查已經20年了,得到的重要經驗之一就是數據會說謊——就像人會說謊一樣,它說謊的幾率甚至更高。畢竟,數據通常是由人創造和維護的。
數據代表了某一特定時刻發生的事實。那麼,怎麼核實一個數據組是否和現實相符呢?
在數據驅動的調查中,我們有兩大驗證任務需要完成:一個是得到數據後必須馬上做初步估算,再一個是當調查或分析階段接近尾聲時,必須要核實結果。
A. 初步驗證
第一條就是對所有人和事物提出質疑。用數據一絲不苟地做新聞時,你會發現沒有一個消息源是完全可靠的。
舉個例子,你會完全信任世界銀行發布的數據庫嗎?我問過的大多數記者都會回答“信任”;他們認為世界銀行是可靠消息源。那就驗證這判斷對不對。我選了兩個世界銀行的數據組來說明如何驗證數據,並向各位強調:甚至所謂“可靠”的消息源也有可能給出錯誤數據。我會沿下圖所示的步驟帶大家一探究竟:

1.數據完整嗎?
我建議第一步先來探究數據集里每個變量的極值(最大值或者最小值),然後計算每個可能的數值里有多少記錄(數據行)。
例如,1964年以來世界銀行在全球有8600多個項目,它為此發布了一個數據庫,收集了1萬條項目獨立評估。
在表格里升序排列“借出款項”這一數據,很快發現多條記錄在這一列居然顯示為零。
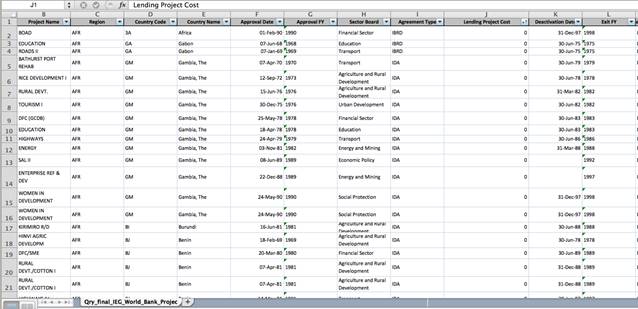
 這就意味着如果項目花費顯示為零的條目得不到合理解釋,任何人在計算或分析每個國家、區域,或年份時引用相關項目支出數據就可能出錯。數據集就會導向錯誤結論。
這就意味着如果項目花費顯示為零的條目得不到合理解釋,任何人在計算或分析每個國家、區域,或年份時引用相關項目支出數據就可能出錯。數據集就會導向錯誤結論。
世界銀行發布了另一個數據庫,涵蓋了1947年以來它所資助的每個項目的單獨數據(不僅僅是估算數據)。

在Excel里打開名為 api.csv 的文件(2014年12月7日的版本),你就會一目了然:數據混雜,一格里包含很多變量(例如領域名稱或國家名稱)。但更值得注意的是:文件並沒有涵蓋所有1947以來的投資項目。
實際上,數據庫只收錄了1947年以來世界銀行15000多個項目中的6352個。(註:世銀最終糾正了錯誤。到2015年2月12日為止,這份文件共收集16215條記錄。)

只是稍微檢查了數據,我們就發現世界銀行的數據庫並沒有收錄所有項目的支出。世界銀行發布的數據雜亂,連一個涵蓋所有項目的數據版本都沒有 。那麼,要是看上去不可靠的機構,你對它們發布的數據質量又能抱什麼期望呢?
我在波多黎各開工作坊期間,發現了另一個數據庫不一致的例子。 我們從審計官的辦公室調用了政府合同數據庫。去年全部的合同中,有72份政府合同在花費記錄上出現了負值($–10,000,000)。
Open Refine是快速挖掘數據庫、檢測其質量的絕佳工具。下面第一張圖中,你可以看到Open Refine可以用於運行 Cuantía (Amount)里一項名為“facet”的數字型字段(numeric)。numeric facet把數值分到相應的範圍組中,你就能選擇任何一個連續區間了。
第二張圖顯示的是你可以用數據庫里的數值範圍生成一個柱狀圖,在表格中移動箭頭篩選數值。可用同樣的方法篩選日期和文本數值。

2.是否有重複記錄?
我們犯的一個普遍錯誤是處理數據時沒辨識出重複記錄。
處理涉及人、公司、活動或交易的分類數據或信息時,首先搜索每條信息的唯一識別項。以世界銀行的項目評估數據庫為例,每個項目都包含一個唯一編碼,或者“項目ID”,以供識別。其他機構的數據庫可能有唯一識別碼,或者像政府合同數據庫那樣,有一個合同編碼。
如果數清楚每個項目在數據庫里有多少條記錄,就能發現有些記錄重複多達三次。因此,任何以每一個國家、區域或者日期為基礎的計算,如果沒有去除重複信息,就會出錯。
 這種情況下,重複記錄的產生是由於每一條記錄都用了多重評估類型,我們必須選擇最值得信賴的評估方式。(在這個例子中,“表現評估報告” [PARs]似乎是最可信的數據,它們讓評估更有說服力。該數據獨立評估小組(Independent Evaluation Group )所開發的,它每年獨立、隨機選取了世界銀行25%的項目做抽樣調查,派專家實地評估項目結果,發布獨立評估報告。)
這種情況下,重複記錄的產生是由於每一條記錄都用了多重評估類型,我們必須選擇最值得信賴的評估方式。(在這個例子中,“表現評估報告” [PARs]似乎是最可信的數據,它們讓評估更有說服力。該數據獨立評估小組(Independent Evaluation Group )所開發的,它每年獨立、隨機選取了世界銀行25%的項目做抽樣調查,派專家實地評估項目結果,發布獨立評估報告。)
3. 數據準確嗎?
確認數據表可信度的最佳方式之一,就是選擇一條記錄作為樣本,將其和現實作比較。
世界銀行的數據庫按理應該收錄了該機構所發起的所有項目,如果我們按每項花費的降序排列這些項目,會發現印度有一個項目花費最多,總額高達298.333億美元 (相當於人民幣1852億元)。
如果我們在谷歌上搜索項目號(P144447),我們就能看到項目和其撥款的原版批准文件,清楚寫着298.33億美元的花費。這說明數字是準確的。
所以最好在記錄中選取大量樣本,一遍遍做數據驗證練習。
 4. 核實數據的完整性
4. 核實數據的完整性
從第一次在電腦里輸入數據,到獲取數據,數據已經走過了輸入、存儲、傳輸和記錄的過程。在每個階段,它都可能遭遇人或者信息系統的篡改。
所以很普遍的一個現象是,數據表之間的關係,或者不同實際調查之間的關係,要麼發生了偏離,要麼混為一體,或者其中的一些變量沒有更新。這就是為什麼我們必須要做完整性測試。
例如,在世界銀行的數據庫里,還有不少多年前就得到批准的項目依然在“活躍”之列,即使很多項目已經結束了。
為了驗證,我創建了一個數據透視表,把每年批准通過的項目分組。接着篩選數據,只顯示那些在“狀態”一列是“活躍”的項目。我們發現1986、87和89年審批通過的17個項目在數據庫里依然顯示為“活躍”。他們幾乎都在非洲。


在此情況下,我們需要直接向世界銀行求證,確認這些項目是否在近30年之後依然活躍。
我們應該使用其他的測試來檢測世界銀行數據的一致性。例如,檢查貸款接收方(在數據庫里顯示的時“借款人”(borrowers))和(或)“國家名稱”(Countryname)標註的國家組織與實際政府是否一一對應。或者看看這些國家分屬的區域是否正確(查“區域名稱”(regionname)一列)。
5. 破譯編碼和縮略詞
嚇跑記者的最好方法之一是給他/她充斥特殊編碼和術語的複雜信息,這是希望隱瞞信息的官員和組織偏愛的伎倆。他們希望我們從公開信息里看不出個所以然。但編碼和縮略詞也有好處:可以減少用詞量,擴充信息容量。幾乎所有數據系統,不論公共還是私人,都用編碼和縮略詞來分類信息。
世界上很多人、機構和事物都有一個或數個專屬編碼。人們擁有身份證號、社保號碼、銀行客戶編號,納稅人識別號,學號,僱員編號等。
例如,一把金屬椅子在世界貿易里的編碼是940179。每條船都有一個IMO編號(國際海事組織編號)。很多事物都有一條獨有編碼:房產、車輛、飛機、公司、計算機、智能手機、槍支、坦克、藥物、離婚、婚姻……
因此我們必須學習如何破解編碼,理解他們是怎麼被用來表達數據庫背後的邏輯,更重要的是,理解他們之間的關係。
全世界有1700萬個貨物集裝箱,每一個都有一條唯一識別碼,我們如果知道識別碼開頭的四個字母和物主的身份相關,就能依此追蹤集裝箱的去向。在這個數據庫里,你可以查詢物主信息。一條神秘編碼的四個字母,就已經打開了獲取更多信息的大門。
在世界銀行記錄評估項目的數據庫里,編碼和縮略詞比比皆是,而令人驚奇的是,機構並沒有發布統一的詞彙表闡述編碼的含義。一些縮略詞甚至已經過時,僅在舊文件里出現。
例如在“資金調度工具(Lending Instrument)”這一欄,根據世界銀行資助項目的16種信貸工具類型,把所有的項目分類:APL, DPL, DRL, ERL, FIL, LIL, NA, PRC, PSL, RIL, SAD, SAL, SIL, SIM, SSL 和TAL 。為了理解數據,有必要弄清楚這些縮略詞的意思。否則你還不知道“ERL”指的是緊急貸款,專門貸給剛經歷武裝衝突或者自然災害的國家。
編碼SAD, SAL, SSL 和PSL和上世紀80、90年代世界銀行爭議頗多的“結構調整項目(Structural Adjustment Program)”有關。該項目貸款給身陷經濟危機的國家,作為交換,這些國家調整經濟政策,以削減財政赤字。(由於在好幾個國家造成的社會影響,這個項目受到諸多質疑。)
世界銀行稱,自上世紀90年代末,他們更重視以“發展”為目標的貸款,而不那麼重視那些旨在“調整”的了。但是,數據庫顯示,在2001年和2006年之間,150多筆批准的貸款標示的是“結構調整編碼”。
這是數據庫的錯誤?還是結構調整項目2000年之後仍在繼續?
這個例子告訴我們:破解縮略詞不僅是評估數據質量的極佳方式,更重要的是能發現公眾關心的故事。
B. 在分析後核實數據
核實數據的最後一步的重點是發現和分析。這或許是驗證過程中的最重要一步,也是驗證故事或初步假設是否站得住腳的試金石。
2012年,我在哥斯達黎加媒體La Nación的跨領域團隊任編輯。我們決定調查一項重要的政府公共補貼,名為“Avancemos”。這項補貼每月為公共學校的貧困學生提供助學金,讓他們免於輟學。
在拿到資助學生信息數據庫後,我們加上了他們父母的名字,然後對照查詢哥斯達黎加的房地產、車輛、薪資和公司相關數據庫。這樣一來,我們就能列出一份完整家庭資產清單。(這是哥斯達黎加的公共數據,可以從最高選舉法院獲取)
我們假設:在16.7萬受資助學生中,一些人的生活條件並不貧困,所以不應該接受每月補助。
在分析之前,我們確保完成對所有記錄的鑒定、清理,也核實了每個人和其財產之間的聯繫。
其中一個發現是: 大約75名學生的父親月收入超過2000美元(相當於12418元人民幣,而非技術工的工資最低標準為500每月美元,相當於3105元人民幣),1萬多人擁有高價房產或車輛。
但實地探訪他們家時,我們才知道數據背後的故事:這些孩子和母親一同生活,的確貧困,因為他們的父親已經拋棄了他們。
沒人在發放教育資助之前詢問過他們的父親。結果,國家調用公共資金,資助了許多被不負責父親拋棄的孩子。
這個故事濃縮了我在數據調查里學到的最有效的經驗:即使最好的數據分析也不能代替現場新聞和實地核查。
 Giannina Segnini 是哥倫比亞大學新聞學院的訪問學者。在2014年2月之前,她一直在哥斯達黎加的媒體La Nación領銜一支由記者和工程師組成的團隊,致力於在收集、分析、可視化公共數據庫的基礎上做調查新聞。從2000年開始,她已培訓了美洲、歐洲和亞洲的數百位記者。
Giannina Segnini 是哥倫比亞大學新聞學院的訪問學者。在2014年2月之前,她一直在哥斯達黎加的媒體La Nación領銜一支由記者和工程師組成的團隊,致力於在收集、分析、可視化公共數據庫的基礎上做調查新聞。從2000年開始,她已培訓了美洲、歐洲和亞洲的數百位記者。
