
Maisy Kinsley 的個人網站,雖然這人並不存在。
最近我聽說某位叫做 Maisy Kinsley 的“記者”在撰寫有關做空特斯拉的報道,並正向相關人士查證消息。我不想在這裡大談埃隆·馬斯克(Elon Musk)如何與做空人士作戰,你也不需要這個。我想說的是,人們可以通過各種方法假扮記者作惡,而 Maisy 正是這樣的例子。

Maisy Kinsley 的個人簡介。
我們都會選擇性地向外界釋放關於自己的信息。這些信息可真可假,對於剛認識的人,我們很難判斷它們的可信度。我們能做的,只能估量這些信息大概需要花費多少時間或金錢。對騙子來說,編造某些信息是輕而易舉的,但有些就要費點心力。
下面,我們來鑒別一些常見的身份信息,以及編造它們究竟需要花費多少心力。
首先,我們來談談推特(Twitter)上的個人介紹和頭像。Maisy 使用的頭像是一張原創的圖片。如果對它進行反向圖片搜索(reverse image search),並不會出現其它關於 Maisy 的照片,也不會出現別人的名字,所以這不太可能是張盜用的頭像。而在個人介紹中,Maisy 自稱為彭博撰稿。
不過這並不足以確認一個人的身份。但我們由此發現了 Maisy 的個人網站,而且看上去十分專業。

Maisy 的個人網站。
Maisy 的網站顯示她是一名自由撰稿人。但像推特上的信息一樣,這些都是她自己說的。不過我們由此找到了她的領英頁面,顯示 Maisy 有194位聯絡人,她甚至是我的三度聯絡人!(我已經有點看煩她的照片了,但讓我們再堅持一會。)

Maisy 的領英頁面。
噢,根據領英,Maisy是斯坦福畢業生!我們不是剛談到有的信息需要花費點心力嘛,看,可不是隨便說說!

Maisy 的教育經歷截圖。
真的,很可能是假的
小結一下以上的信息:它們正變得越來越不可信。在互聯網時代,編造這些信息正變得越來越容易,而這也令信息的可信度在下降。
你完全可以決定如何在推特上介紹自己。沒有哪家公司頁面或者專業名錄會刊載這段個人簡介。所以,這樣的信息並沒有足夠的可信度。
那麼 Maisy 的頭像又是怎麼回事呢?這完全要歸功於機器學習,它們已經能創造出一個根本不存在的人士的照片。通過這個網站,你也能花上幾秒鐘創造一張假照片。下面是我的示範。

那 Maisy 的網站呢?網站域名很便宜,一年的租金大概是12美金。而網頁就更便宜了。至於頁面設計,雖然你一半的格調都跟你的網站看起來多專業有關,所以你需要花錢請設計師——但這只是在15年前,今天,你能找到大量免費的模板做出跟 Maisy 一樣的網站。
也許你要問,那領英的頁面呢?那些聯繫人、在斯坦福上過學又是怎麼一回事呢?
首先,領英頁面上的的教育信息一點也不比推特更權威。雖然它看起來很官方,但其實你愛寫什麼就寫什麼。你看,我就剛剛讓自己上了斯坦福,而且讀的是超酷的天體物理學。

我在領英上給自己加上了斯坦福大學的學位——不過截圖之後我立刻刪除了它。
至於 Maisy 在領英上的人脈,就要比上面那些信息好玩一點。有人曾致電他們詢問是否真的認識 Maisy。不,沒人認識,他們只是沒有拒絕對方發來的聯繫邀請或者認證請求罷了。只要 Maisy 向足夠多的人發送聯繫邀請,以及主動為足夠多的人進行認可背書,自然就會有人答覆他的邀請或者認證她。大功告成。

跟你們講一件好玩的真事。有一次我在領英上加一位叫 Sara Wickham 或者類似名字的人做好友。我們聊起在1993年讀大學的朋友:
“記得 Russ 嗎?”
“那個背着吉他,總是彈 The Dead 和 Camper Van Beethoven 的那個傢伙嗎?。”
“你是說 Chris 嗎?”
“是的,Chris!”
“當然記得,他怎麼樣啊?”
聊了一個多星期之後,我意識到我們並不是同學,而且隨着越聊越多,我想起彈吉他的人也根本不叫 Chris。我從來沒見過這個和我聊天的人,我們也根本沒有共同朋友。
這就是領英,聯繫人根本無法說明什麼。
假的,很可能是真的
看到這,你大概早已按捺不住,急着要說你早就注意到 Maisy 有些不妥的地方。你可不會被騙,對吧?
比如說,Maisy 在領英上的經歷顯示她從畢業到成為記者,中間有5年的斷檔期。她2013年畢業,但卻直到最近才成為記者,說不通對吧?她的相片有某種膨脹感,這正是 AI 處理過的痕迹!而且她在哪都是用同一張照片,網站上的個人簡介看起來就像瞎扯。她的工作室叫“不偏不倚的自由工作者及報道者”,聽起來就像“誠實的自助服務”一樣,完全是胡編亂造。
怎麼說呢,指出這些不妥並不會顯得你有多聰明。畢竟你已經知道 Maisy 是個騙子,所以自然會注意到各種不合理的地方。
問題在於,當我們用放大鏡來審視生活時,就會發現它就是充滿着各種不合理。比如工作出現斷檔,可能是因為他有了孩子。在畢業後與第一份正式工作之前出現斷檔,是很常見的現象,特別是對於女人來說。如果你覺得這就說明別人是騙子,那麼一大群很棒的女記者都會被你標籤為騙子。
至於照片,有時候人們就是會用一些怪怪的照片。以下是在推特上很活躍的 Joshua Benton 使用的頭像。

Joshua Benton 的推特頭像。
Joshua 在推特的個人簡介中聲稱自己是哈佛某個媒體項目的負責人。然後他竟然用了一張這樣的頭像,絕對是騙子,對吧?
但事實上,他的確在哈佛工作,而且負責一個世界知名的實驗室。
那 Maisy 糟糕的簡歷又怎麼解釋呢?嗯,難道你沒試過寫了一個糟糕的簡歷,然後想着自己過段時間會再修改嗎?我就干過這事。(然後很多會議項目就刊登了這份簡歷)
至於她的私人工作室名字——不偏不倚的自由工作者及報道者,真的就能說明是騙子嗎?
講個好玩的事給你們聽,一群推特用戶參與調查了 Maisy 假扮記者這事,也檢視了她在領英上的聯繫人及背書者。其中有一位 “牧羊人先生” 似乎一看就是騙子。他還自稱是狗狗攝影師及紙制帽子匠人。
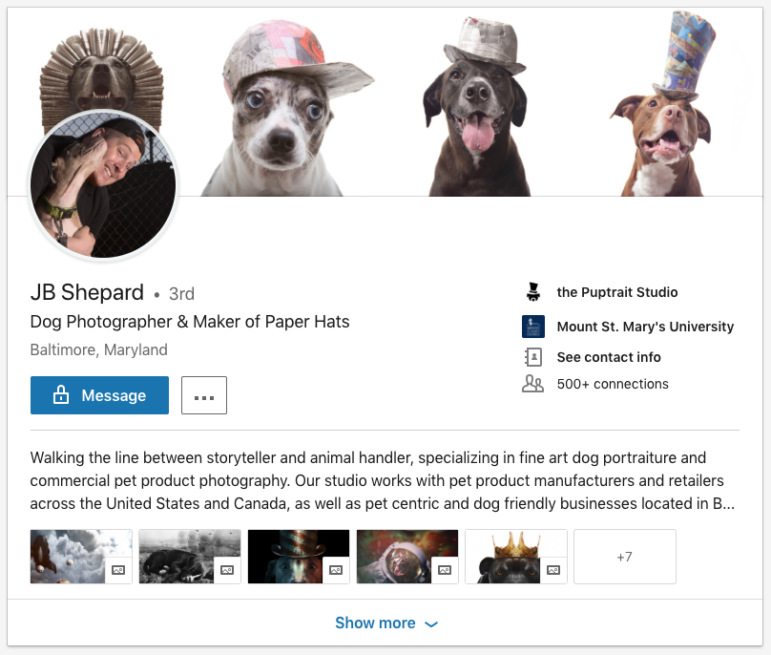
不用我一一分析給你聽,對吧?這個人姓謝帕德(Shepard,英文意思是牧羊人)。他上傳的帽子照片一看就是PS過的,他的自我介紹是“身處說故事的人及動物管理者之間”。這肯定是騙子。
人們真的打電話去謝帕德(JB Shepard)先生的 Puptrait 工作室,然後發現都是真的,他真的是姓謝帕德。

圖中這隻小狗真的存在,真的帶着紙做的帽子,而且都可愛的不得了。如果你想幫自己家的動物也拍一張類似的照片(或者在這個讓人心煩的世界裡看看可愛的小東西解解悶)你可以聯繫牧羊人先生的Puptrait工作室。感謝JB·牧羊人先生同意我們刊登這張照片。
這頂紙帽子也不是PS的,而是謝帕德先生真的為這隻小狗量身製作的。
如果你也曾經認為謝帕德先生是個偽造的身份,別怪責自己。當你接觸看起來很粗製濫造的信息時,你對他們的真實性或者可信度的判斷,會受到固有思維的影響。如果你是男人,就很有可能會覺得工作空白期不可能長達5年。而當你並不是狗狗攝影師以及紙質帽子匠人時,就會覺得這聽起來不像什麼正經工作。
我曾在同事和學生身上做過實驗:我們告訴他們某個網站是偽造的,然後詢問他們哪些線索可以有助我們判斷這一點。他們常常會很快總結出幾十個明顯的漏洞:太多廣告、奇怪的排版、域名、沒有受訪者的相片、標題黨、沒有清晰的“關於我們”的頁面等等。然後我就會告訴他們這個網站是真實的,而且屬於某個世界知名的醫學周刊或者是刊載澳洲國家記錄的報刊。
但我現在放棄這個實驗了。原因很多,比如人們會生我的氣。他們有理由生氣,畢竟我捉弄了他們。
不過阻止我做實驗的主要原因在於,當人們通過種種跡象判斷某個網站是偽造的之後,即使我指出這些網站是真實的,也會難以說服所有人。每一條“線索”都讓他們更堅持自己的想法,即使我告知他們這個網站可信度很高,但也沒有多大作用。他們會和我爭論,認為這不可能是權威的醫學期刊。他們會說,我不相信你,你一定是哪裡弄錯了,你需要再次查證自己的信息!
我們的爭論佔用了太多課堂時間,最後我選擇改用其它的教學方法,但這段經歷令我想起來都有點後怕。
什麼是真正的關鍵信息?
大量質量不佳的簡單信息會影響你的判斷,甚至會讓你更加困惑。當你越試着去判斷它們孰真孰假時,往往只會變得越來越迷惑。
這種情況將變得更加嚴重。目前我們還能根據一些典型特徵去判斷某張圖片是否由人工智能生成,但這些法子很快將會失效。現在你還要自己去寫網站上的個人簡介,但機器學習會很快寫出看起來更可信的自我介紹,甚至比你自己寫的還要真實得多。到時候,編造這些信息不僅是容易,應該是毫不費力。
要提高人們在數字時代辨析信息的能力,我的建議是停止那套老方法。大量搜集信息,然後在受到固有思維影響的複雜框架中去分析它們已經不管用了,我們要做的是學會藉助互聯網的特性做出快速判斷。
還是以那位假記者為例。她聲稱自己為彭博社寫稿。
Maisy的個人簡介。
這是真的嗎?她在哪發表過文章呢?我的調查結果如下:

在 Google News 檢索的截圖。
我在谷歌新聞中檢索“Maisy Kinsley”,但完全沒有關於她的條目。既沒有相關的署名,也沒有由她撰寫的故事。當你在彭博的官網上搜索時,同樣一無所獲。
我們可以用同樣的方式搜索一位最近聯絡我的 BBC 記者。這是谷歌新聞的搜索結果,首先是一些他為福布斯撰寫的文章:
在谷歌新聞搜索 Frey Lindsay 時,出現了許多他為福布斯撰寫的文章。

在谷歌新聞中搜索 Frey Lindsay 可以看到許多他的作品。
再往下翻時,會看見他寫的其它文章,中間也包括為 BBC 撰寫的:
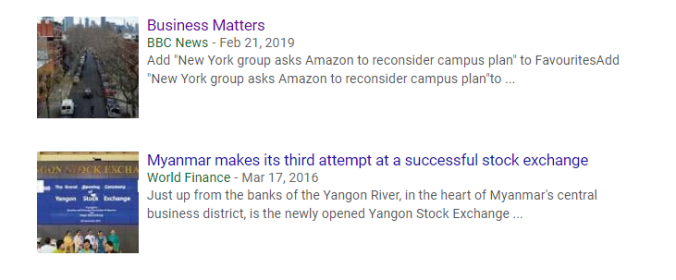
如果我們點擊鏈接前往 BBC 官網,再次搜索他的名字時,會找到更多他寫的新聞:
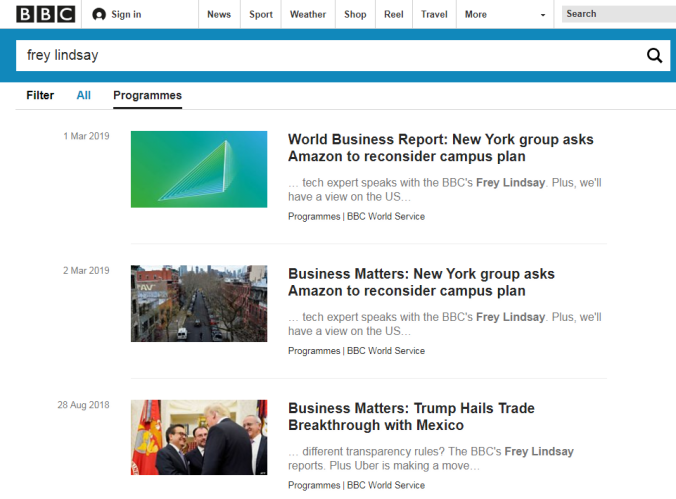
我們不用去管那些瑣碎的信息,比如說他的相片、個人網站、領英頁面有沒有問題,也不用去管他的公司名字怪不怪,或者工作空白期是否合理。這些雞毛蒜皮的信息,Frey 能輕易偽造(如果他真是騙子),而我們也容易誤讀(如果他不是騙子)。我們要做的是找到能證明 Frey 是記者的信息。這些信息不是 Frey 自己說的,而是互聯網所展示的。真相真的“就在那裡”:就在網絡上,你要學習的是利用網絡去找到它們。這要求你懂得什麼信息容易偽造:比如領英上的聯繫人、自我簡介的頁面、相片等等);什麼信息難以偽造:比如在權威的、明顯有專人打理的網站上刊載的報導等等。
要提高人們在數字時代辨識信息的能力是件不容易的事。人們習慣通過某些信息來進行判斷,但到了網絡世界,這些信息要不就是難以找到,要不就是極容易被偽造。要學會區分哪些才是網絡上重要的判斷依據,是一項少人掌握的技能。你必須知道谷歌新聞的展示機制,哪些結果是有效的,哪些是無效的。你得知道人們可以花錢買粉絲,推特上的認證信息只說明你說自己是誰,但無法證明你說的是事實。你得知道偽造一大串社交媒體使用足跡要比偽造一長串個人歷史容易得多,而且為了讓他們的信息在搜索頁面置頂,騙子還能誘騙你使用他們想要你使用的搜索關鍵詞。
我們常以為接受過良好的教育,就會擁有所謂的“批判性思維”。這個看似無所不能的靈藥能讓我們無論在哪都暢通無阻。的確,有些認知能力能放之四海而皆準,但更多時候在特定情況下才有效,而且需要學習才能掌握。在多年的數字素養研究生涯中,我仍然堅信:在藉助網絡辨識信息可信度方面,我們仍然有很長的路要走。
本文首發於 Mike Caulfield 的個人網站 Hapgood,全球深度報道網獲授權編輯轉載
 Mike Caulfield 是華盛頓州立大學溫哥華分校混合和網絡學習的負責人,也是美國數字兩極化項目的負責人,該項目是一個旨在改變媒體素養教育的多學校試點項目。
Mike Caulfield 是華盛頓州立大學溫哥華分校混合和網絡學習的負責人,也是美國數字兩極化項目的負責人,該項目是一個旨在改變媒體素養教育的多學校試點項目。
