
圖:Pixabay
追蹤和報道新聞時,記者需要保護消息來源的身份。許多的重磅報道都堅守着這個規則,即便是在披露關鍵信息和保護消息來源(特別是當消息人士正面臨人身安全風險)之間取得平衡通常不易。
當今這個無處不在收集數據的時代,這種挑戰尤其凸出。計算機技術的發展,讓人們可以處理海量數據,同時造就人們以數據牟利、實施監控等。在眾多事例中,原來被視為基本需求的個人隱私反而被視作障礙。從“劍橋分析”(Cambridge Analytica)挪用個人數據進行定點廣告投放,到智能設備被用於侵入式數據跟蹤,眾多事例反映出,隨着數據不斷被盜取和外泄,人們似乎對保護隱私逐漸麻木。
當可獲取數據前所未有的多,記者在報道時也愈來愈依賴數據。不過,記者除了考慮怎樣保護機密消息來源,也要衡量如何發布數據,才不會泄露不必要的個人信息。就大多數新聞故事而言,記者可能有需要披露部分個人信息,但沒必要點名龐大數據中的每個個體,如是者可以採取“去識別”(de-identification)或“匿名化”(anonymization)來保護個人隱私。
何謂個人信息?
雖然2000年代末期的法律改革確立了對個人信息的定義,但有意無意的數據外泄事件依然持續發生,並且危害着個人隱私,而新聞工作者長期扮演揭發這些外泄事件的重要角色。“美國線上”(AOL)於2006年公布數以百萬計的網絡搜尋數據,記者單憑個人搜尋記錄,包括健康狀況、約會偏好等敏感信息,就能整理出個別人士的身份信息。同樣,中央情報局前僱員斯諾登(Edward Snowden)披露美國國家安全局(NSA)的大規模監控行動之後,各項研究紛紛揭示通信元資料如何被用於識別及監控通訊設備用戶。
當記者決定以數據集作為新聞故事的消息來源,他們就肩負起權衡信息敏感度的責任。要作出準確的評估,首先要了解什麼是個人信息,什麼不是。
“個人可識別信息”(Personally identifiable information,PII)在歐洲法律上以“個人數據”(personal data)來指涉,而在其他部分司法管轄區則以“個人信息”(personal information)來指涉。“個人可識別信息”通常被理解為可以直接識別個人的任何信息,這些信息按不同程度的可識別度和敏感度,處於圖譜上的不同位置。例如,姓名、電郵地址等信息的可識別度高,但低敏感度低,發布這些信息通常不會危害個人;相對地,位置數據、個人健康記錄等信息的可識別度低,但敏感度高。為了方便說明,我們可以因應可識別度和敏感度,在圖譜上定位各種類型的“個人可識別信息”。
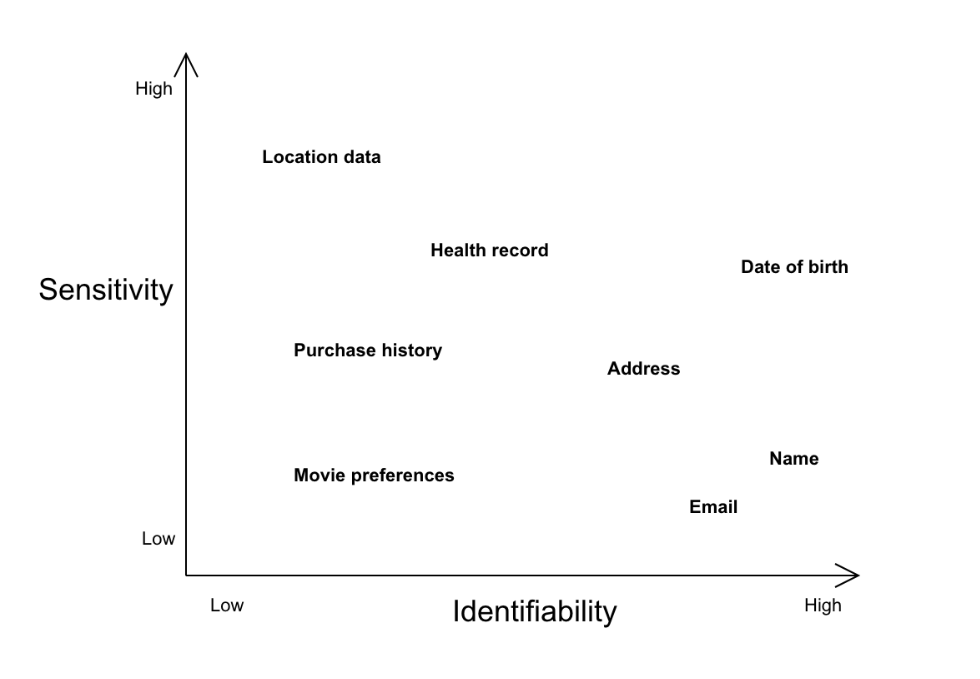
“個人可識別信息”通常被理解為可以直接識別個人的任何信息。圖:Datajournalism.com
“個人可識別信息”的可識別度和敏感度,同時取決於文本背景和數據混合後產生的複合效果。例如,發布 Facebook 粉絲數據庫中的某君姓名,可能只會產生低風險,但發布一份政治異議人士名單上的某君姓名,帶來的風險就會大大增加。多項數據結合應用時,信息的價值也會出現變化,例如單看一個購買記錄數據庫,很難連繫到任何特定個人,但結合位置信息或信用卡號碼,可識別度和敏感度則會大大提高。
2016年有這樣的一個事例:澳大利亞衛生部發布了一批“去識別”藥物數據,數據限定用於學術研究,只讓學者解密部分信息;然而當地隱私專員認為,這依然構成個人信息被曝光的可能,因此介入調查。同樣在2016年,BuzzFeed 就職業網球員的欺詐行為進行調查報道,並且發布了經過“匿名化”處理的相關數據;然而,一群大學生結合利用其他公開數據,成功“再識別”出報道中沒有點名的涉事網球員。這此事例說明,新聞工作者要準確判斷數據集中的個人信息性質,就必須兼顧評估數據集包含的信息,以及可能已經公開的其他信息。

儘管這些網球球員的姓名經過了匿名化的處理, 然而,一群大學生結合利用其他公開數據,成功“再識別”出報道中沒有點名的涉事網球員. 圖:Datajournalism.com
何謂“去識別”?
為了隱藏消息來源的身份,新聞工作者可能會以匿名或化名來處理,例如“水門事件”報道中所使用的“深喉”(Deep Throat)。處理信息時,刪除個人信息的過程被稱為“去識別”(de-identification),或在一些司法管轄區被稱為“匿名化”(anonymization)。早在互聯網誕生前,新聞工作者已在應用“去識別”技術,例如在外泄文件上塗掉某些姓名。時至今天,新聞工作者配備了更多嶄新的“去識別”方法和工具,可以在數字環境中保護隱私,同時更便於分析和處理前所未有的龐大數據。
“去識別”的目的就是防止“再識別”(re-identification),換句話說就是將數據“匿名化”,令數據無法被用於識別任何個人。雖然“匿名化”在法律上存在一些定義,但實質的規範和操作,通常建基於不同行業的規矩。例如在美國,醫療保健記錄受《健康保險便利和責任法案》(HIPAA)的規範,病人姓名、住址、社會安全號碼等直接標識必須經過“匿名化”處理。而在歐盟地區,《一般資料保護規範》(GDPR)規定姓名、住址、電郵地址等直接標識,以及工作職銜、郵政編碼等間接標識,均要作“匿名化”處理。
編寫新聞故事時,記者需要判斷哪些信息屬於關鍵,哪些信息可以忽略。一般來說,愈有價值的信息愈是敏感。例如,醫學研究人員必須掌握臨床診斷數據和其他醫藥數據,儘管這些數據很可能與特定個人存在聯繫,屬於高度敏感數據。為了在數據的實用性和敏感度之間取得平衡,記者在決定發布哪些內容時,可以採取適用的“去識別”技術。
數據改寫(Data Redaction)

一份 CIA 數據改寫的文檔. 圖片: Wikimedia
最簡單的數據庫“去識別”方法,是直接刪除所有個人或敏感數據。“數據改寫”存在一個明顯的缺點,就是可能丟失一些有價值信息,不過這種方法一般用於處理直接標識,例如姓名、地址、社會安全號碼,而這些數據通常並非新聞故事的癥結所在。
然而,隨着科技日益進步及可用數據不斷增加,間接標識的可識別度也持續提高。單靠“數據改寫”來處理直接標識,往往會忽略間接標識,因此記者不應以此作為“去識別”的單一手段。
假名化(Pseudonymization)
某些情況下,“數據改寫”會破壞數據的實用性。要解決這個問題,可以採取“假名化”,也就是以隨機或演算法生成的假名來替代可識別數據。“假名化”的最常用技術是雜湊(hashing)和加密(encryption),前者利用數學函式將數據單向轉換成不可讀的散列信息,後者則以雙向算法轉換來處理數據。換言之,雜湊與加密的主要區別在於,前者是不可逆向破解的,而後者可憑正確金鑰來解密。許多數據庫管理系統,例如 MySQL 和 PostgreSQL,都同時提供雜湊和加密兩種數據處理方法。
在國際調查記者同盟(ICIJ)進行離岸解密調查的過程中,數據“假名化”發揮了重要的作用。由於記者需要處理海量數據,他們依賴於外泄文件中每個個人與實體之間的獨特代碼,來辨識不同個人和實體之間的關係,即使兩者名稱並不匹配,這些“假名化”代碼也能發揮作用。
信息怎樣才算經過妥善的“假名化”處理?答案是在不參考其他數據之下,該項信息無法再被連繫上某個個體。換句話說,當“假名化”數據與其他數據被集結在一起相互參考,“假名化”作為“去識別”手段的效能依然有可能被削弱。就算是在整個數據集中重複使用相同的假名,由於假名每次出現,找出變項之間關係的機會就會提高,“假名化”的效能也會因此減低。還有一些情況是,用於生成假名的演算法有機會被第三方破解,或者演算法本身就有漏洞。因此,新聞工作者採取“假名化”來隱藏個人數據時,還是應該格外慎重。
統計噪聲(Statistical Noise)
由於“數據改寫”和“假名化”均存在被“再識別”的風險,人們經常會配合“統計噪聲”一併運用,例如“k-匿名化”(k-anonymity)。這種方法以一個間接標識來指涉一定數量的個體,最佳做法是對不少於十個條目使用同一個獨特標識,從而使“再識別”變得困難。在數據集加入“統計噪聲”的最常用技術是“概括化”(generalization),例如以大洲替代國家名稱、以數值範圍替代準確數值等。
此外,“數據改寫”和“假名化”經常與“統計噪聲”一併應用,以確保數據集中不存在唯一的標識組合。在以下的例子中,個別行例的數據經過概括或刪除處理,防止特定條目被“再識別”。
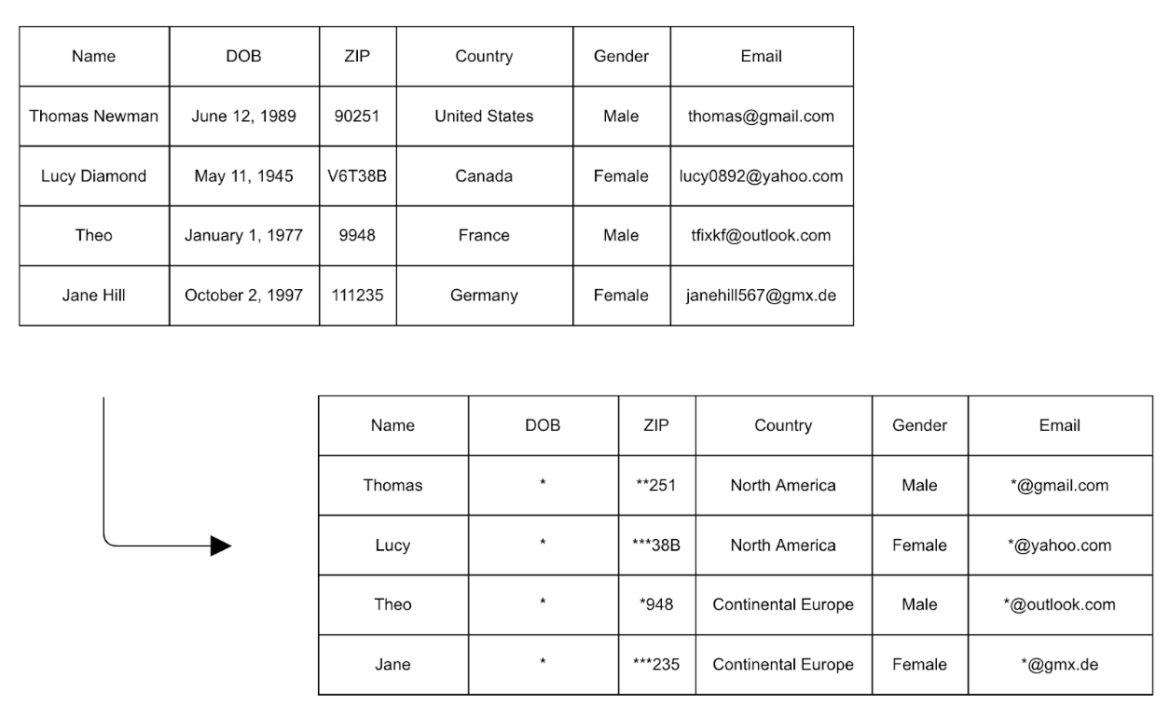
通過“統計噪聲”可以防止數據被“再識別”. 圖: Datajournalism.com
數據匯總(Data Aggregation)
假如沒有必要保留原始數據的完整性,記者可以通過“數據匯總”來進行“去識別”,例如以摘要形式發布數據,從而省略任何直接或間接標識。進行“數據匯總”時,主要考慮是匯總份量是否夠大,是否足以隱藏當中的特定個體。假如能將多個維度的匯總數據組合在一起,“去識別”的效能也會更大。
“去識別”的工作流程
臨近截稿死線,不少記者會忙於評估數據質量、決定如何將數據圖像化,而將數據的“去識別”工作置於次要。不過,在新聞發布過程中保障個人隱私還是至關重要的,特別是個人數據的不當處理可能會破壞新聞作品的可信度,而負責收集和處理相關數據也可能要承受相關法律責任。因此,新聞工作者應該採取以下步驟,將“去識別”納入工作流程:
- 我的數據集中,是否包含個人信息?
假如你處理的是天氣數據、體育統計數據等公開信息,自然毋須煩惱如何進行“去識別”;假如涉及個人姓名、社會安全號碼等數據,披露隱私的風險則會明顯提升。我們更常遇到的情況是,必須經過仔細檢查,才能確定數據到底是否涉及個人信息,特別是當我們處理的是外泄數據,正如 Susan McGregor 和 Alice Brennan 在這篇文章所介紹的。除了直接標識,新聞工作者還應密切注意數據集是否存在間接標識,例如 IP 地址、工作信息、地理位置記錄等。根據經驗,任何與個人有關的信息,都應被視作存在披露隱私風險,並採取相應措施。
- 這項數據有多敏感?可識別度有多高?
個人信息存在多少披露隱私風險,取決於它所存在的文本背景,包括它能否與其他數據對照解讀。因此,新聞工作者需要評估兩件事:一、數據的可識別度有多高;二、數據中的個人隱私有多敏感。
記者可以自問:某人會否因為與這則新聞故事的關連,而面臨安全或聲譽受損?手頭上的數據,有可能被結合其他數據一併解讀,進而令某人的身份曝光嗎?假如是這樣,發布這些數據能夠帶來的公眾利益,是否大於披露隱私所產生的風險呢?當然,就不同的事例還要採取不同的處理方式,才能在公眾利益與個人隱私之間取得平衡。
- 該以怎樣的方式發布數據?
互聯網誕生之前,新聞工作者通過印刷物發表報道,不必為怎樣發布數據而煩惱,因為讀者無法通過印刷圖表和統計數字追查背後的數據信息。隨着數據新聞學進佔前沿位置,先進工具、互動視頻等,讓讀者可以考究新聞故事所採用的數據信息。例如許多記者選擇開源方式,在 GitHub 上分享代碼和數據。為了兼顧保護隱私,開源時務必仔細清除數據中的所有個人信息。至於數據圖像化,一些新聞工作者會藉助混淆原始數據集的預匯總數據來保障隱私,其中關鍵是檢查這些匯總項目是否超過可識別的最低門檻。
- 該採取哪一種“去識別”技術?
新聞工作者一般要結合使用多種“去識別”技術,才能妥善處理手頭上的數據。對於直接標識,如能正確採取“數據改寫”和“假名化”,一般就足以保護個人隱私。對於間接標識,可以考慮將數據歸納成組,或者將非關鍵信息“概括化”,也就是加入“統計噪聲”。對於高度敏感數據,“數據匯總”是最佳選項,不過必須確保數據的範圍夠廣、匯總變項的分布夠均勻,從而保證個人信息不在無意中外泄。
以身作則:我們沒有借口迴避“去識別”工作
數據一經網絡發布,就沒有修訂或更正的餘地。即便你認定已經清除數據集的所有個人信息,依然會存在風險——某地某人可能結合你的數據和其他來源的信息,成功“再識別”特定個體,或者破解你的“匿名化”演算法,成功曝光背後隱藏的個人信息。另外,機器學習、圖型識別等技術持續進步,也發展出令人意想不到的組合和轉換數據新方法,令個人信息被“再識別”的風險持續提升。
要謹記的是,就算是看起來不像個人信息的數據點,只要結合其他數據,也有可能被用於“再識別”。當網飛(Netflix)推出“網飛獎”,公開徵集最佳的協同過濾演算法時,也標榜可用數據不存在任何個人信息標識。然而,外界還是能夠通過比對參照網路電影資料庫(IMDb)等網上來源的數據,例如個人觀影偏好信息,來識別網飛號稱“匿名化”數據集中的特定個體。
雖然現存的各種“去識別”技術都有局限,新聞工作者仍然應盡最大努力保護個人隱私。以身作則,國際調查記者同盟處理海量的個人數據時,始終注重保護隱私。來自任何背景的新聞工作者,都沒有不採取類似措施,以平衡個人隱私與公眾利益的借口。
再者,從婚外情社交網站 Ashley Madison 資料外泄所引發的眾多個人悲劇,到“維基解密”(Wikileaks)所曝光的大量敏感數據,已有太多例子顯示,不採取保護隱私的措施,就有可能導致個人信息外泄,進而引起掀然大波。因此,新聞工作者應該倡導負責任的數據處理方法,以避免重蹈覆轍。
本文首發於 Datajournalism.com,全球深度報道網獲授權編譯轉載。
 Vojtech Sedlak 是數據科學家,目前任職於非營利組織 SumOfUs,組織以制衡持續壯大的商業企業力量為宗旨。Vojtech Sedlak 曾在 Mozilla 及 OpenMedia 工作,熱衷於 RStudio、measure slack、開放資料社群,也是開源代碼分析的忠實擁護者。
Vojtech Sedlak 是數據科學家,目前任職於非營利組織 SumOfUs,組織以制衡持續壯大的商業企業力量為宗旨。Vojtech Sedlak 曾在 Mozilla 及 OpenMedia 工作,熱衷於 RStudio、measure slack、開放資料社群,也是開源代碼分析的忠實擁護者。
