
图:Shutterstock
ProPublica 的克雷格·西尔弗曼(Craig Silverman)在这篇文章中分享了如何批量存档网页,比较更改以及查看页面元素何时被存档。
在上一期的《数字调查》(Digital Investigations,一份由西尔弗曼运营的新闻信)为如何充分利用 Wayback Machine(网站时光机) 提供了建议。在今天这篇文章中,我又带来了更多使用 Wayback Machine 的使用技巧,这得益于我对 Wayback Machine 负责人马克· 格雷厄姆(Mark Graham)的采访。
他指出了我在上一篇文章中忘记提及的一些功能,以及一个我不知道的功能。我们还讨论了存档社交媒体内容的挑战。
Wayback Machine 由互联网档案馆(Internet Archive)运行,这是一个成立 27 年的非营利组织,致力于为所有知识提供普遍访问。 “我们是一个数字图书馆,”格雷厄姆说。
他说,作为一个图书馆,Wayback Machine 所拥有的是赞助者而不是用户。让我们看看 Wayback Machine 中一些对于记者和研究人员最有用的功能。
1. 查看并比较更改
“更改”功能让你可以比较同一存档页面的不同版本,并看到其中的差异。
“可能有一位新闻记者正在写一篇报道,展示网页上的内容是如何随着时间的推移而变化的,”格雷厄姆说,“在这种情况下,他们需要了解 Wayback Machine 的‘更改’(Changes)功能,你可以比较同一 URL 在两个不同时间点上的内容。”
“更改”功能可以从你在 Wayback Machine 中浏览的任何存档页面的顶部菜单中访问:

图:Wayback Machine 截图
你也可以直接通过这种URL格式加载它: https://web.archive.org/web/changes/https://www.nytco.com/journalism/
将你想要进行查看的网址放在 https://web.archive.org/web/changes/ 后面,它将显示一个按年归档的网格页面:
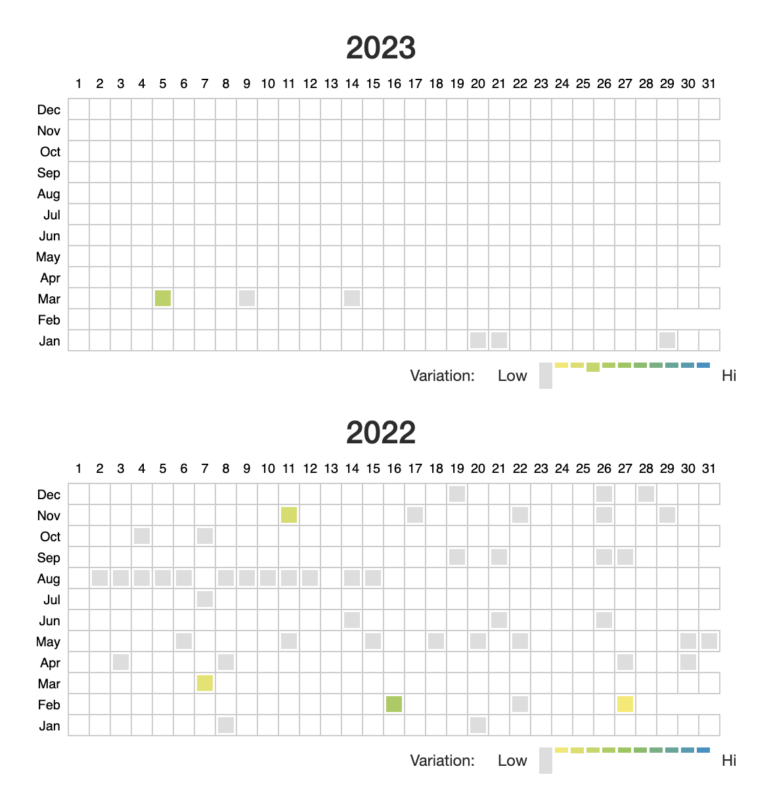
图:Wayback Machine 截图
每个阴影方块都对应一个网页快照,颜色图例表示哪些天可能网页内容出现了重大变化。选择两个截图,然后点击页面顶部的“比较”(Compare)按钮,你就会到到一个并排显示的网页快照。
我选择了2023年3月初的一页(左)和2022年1月初的一页(右)。“比较”结果显示,《纽约时报》关于其新闻业务的页面更新了底部菜单选项和文本:
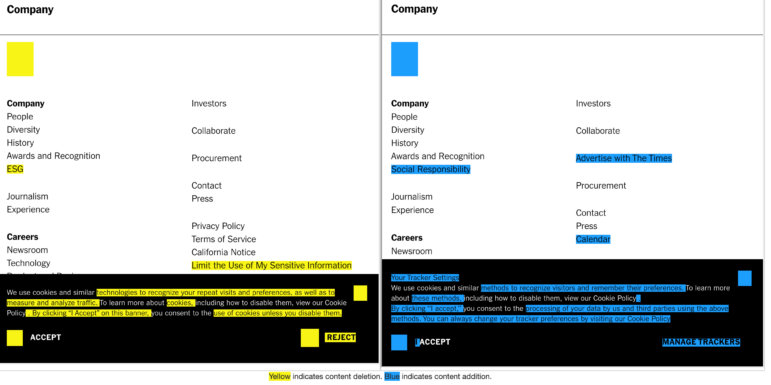
图:Wayback Machine 截图
2. 使用“关于此捕获”来验证网页元素
Wayback Machine 的基本功能是捕捉和储存网页快照,但实际它的用途更为微妙。
“网络是混乱的,网络在不断变化,”格雷厄姆说。“当我说不断变化时,指的是它也可以是动态的。”
我问他,我们如何确认网页快照显示的正是 Wayback Machine 中列出的日期和时间的页面内容。简单的答案是,是,你可以有这个信心。但归档页面的元素可以从不同的归档材料中获取,每个都有自己的时间戳。这就是 Wayback Machine 的微妙之处。
Wayback Machine 有一个功能,可让您查看网页上不同元素的时间戳。您可以通过点击页面网页快照右上角的“关于此捕获”(About this capture)按钮来访问它:
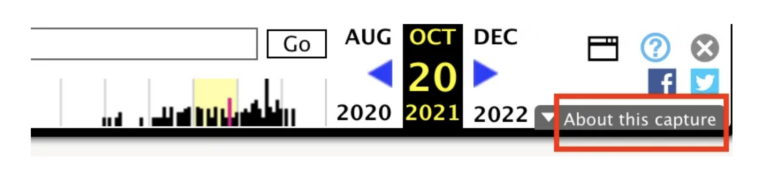
Image: Screenshot
以 https://www.nytco.com/journalism/ 为例,我们得到以下结果:
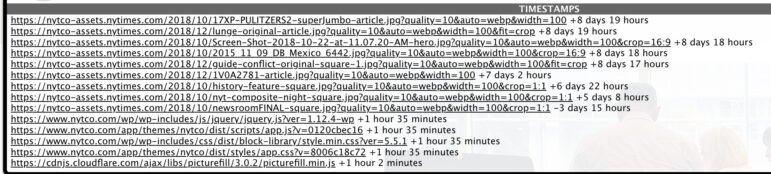
图:Wayback Machine
尽管该页面在2021年10月20日被存档,但 Wayback Machine 会从较新的网页快照中提取一些元素。上面列出的大部分网页元素都是静态图像,还有几个 JavaScript 和 CSS 文件。格雷厄姆解释说,当你在查看一个网页时,Wayback Machine 会从不同的图像、JavaScript 和 CSS 文件中提取内容以生成页面。
“当我们重现一个页面时,我们实际上是把每个具有自己的URL和自己的存档的页面要求收集起来,然后把它们放在一起,”他说。“其中一个挑战是,这些对象中的每一个可能在不同的时间和日期被存档。”
“当我们‘回放’一个页面时,我们实际上会将收集到的每个网页快照和这个 URL 的实时访问状态放到了一起,”他说。“其中的一个挑战是,每个静态对象可能会在不同的时间被归档。”
例如,网页顶部的主照片(“17XP-PULITZERS2-superJumbo-article.jpg”)是从我加载归档 8 天前抓取的。如果那张照片/文件对你的调查很重要,你可能需要检查当时的归档页面,看看它是否随着时间的推移发生了变化,或者寻找一个更接近目标日期的快照。但只要那个文件在每个时间点都保持不变,就没有问题。
{kind=link}
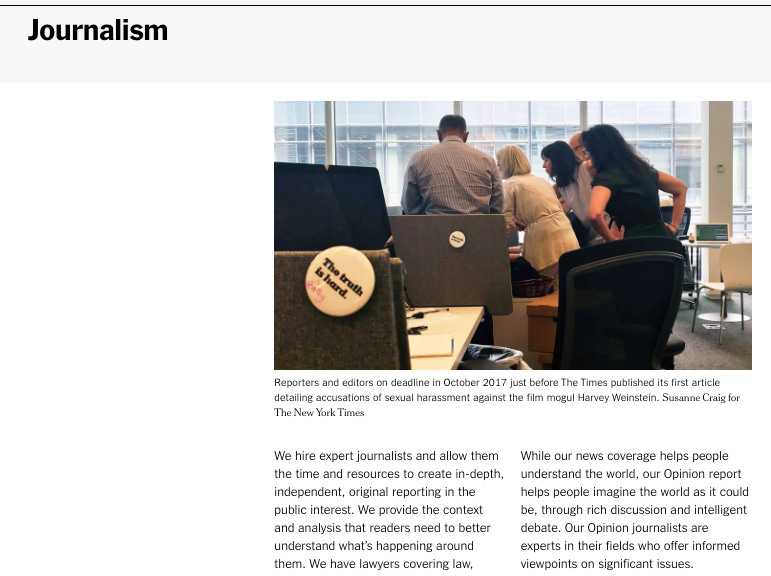
图:《纽约时报》网站
作为一条普遍但并非绝对的规则,典型网页的正文通常不会从另一个页面或文件中提取。因此,它不太可能受到这种动态性的影响。但最安全的做法还是检查“关于此捕获”,并确保你引用的页面捕获中的文本、图片或其他元素与你想要查阅的日期一致。
3. 使用 Google 表格对网址进行批量存档

图:互联网档案馆
一旦完成,您将看到下图,这个时候点击“归档网址”(Archive URLs)。

图:互联网档案馆
现在,你可以将 Google 表格的链接复制粘贴到相应位置。
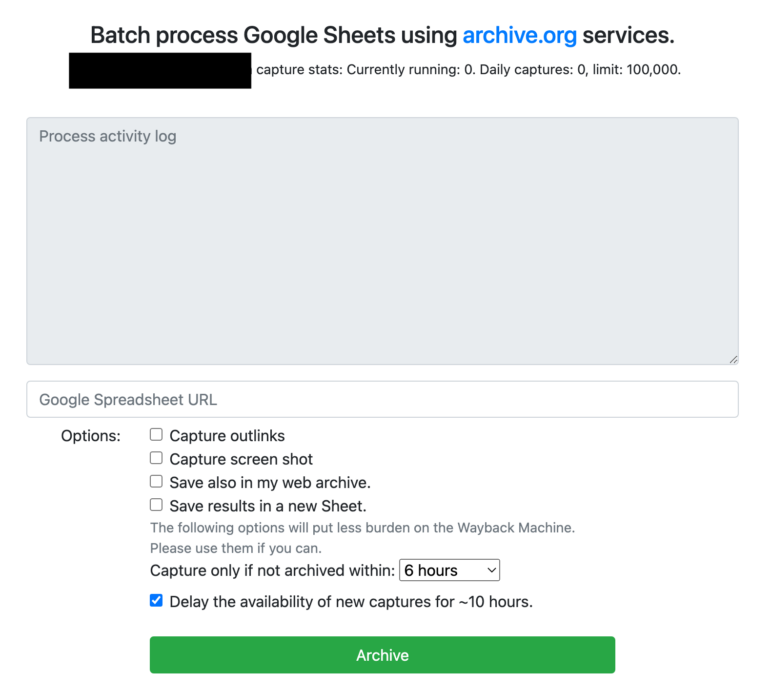
图:互联网档案馆
从你将 Google 账户和 archive.org 账户连接起来后,你所捕捉的所有网页快照都将存储在你的 archive.org 账户中,方便你查阅。
他说:“这个功能的出现是因为有一天我的妻子问我,‘马克,我怎样才能轻松地归档一堆 URL?’?”
格雷厄姆与互联网档案馆的工程师们合作,让 Wayback Machine 实现了这个功能。
4. 发送你的反馈和建议
“由于用户的要求、提问或建议,如今的 Wayback Machine 有了许多的功能,”格雷厄姆说。“我们非常感谢这些反馈和建议。现在很多功能都是因为用户的请求才开发的。我们非常欢迎用户的反馈和建议。”
他鼓励人们发送邮件到 info@archive.org 进行反馈和建议 。
“我们每天收到数百封电子邮件,我们有一个团队专门负责查阅和回复这些邮件,”格雷厄姆说。“我个人会回复那些无法由这个团队直接处理的邮件。”他也特别鼓励记者们在有问题或请求时主动和他们联系。
额外内容:归档社交媒体信息
Wayback Machine 的资深用户会知道,在上面存档社交媒体内容的难度非常高,这和 Wayback Machine 自身的功能和限制关系不大,而是与像 Meta 这样的公司阻止内容抓取有关。
这是格雷厄姆关于为什么很难从社交媒体存档内容的原因的解释:
就像一些网站比另一些网站更难存档一样,特别是 Facebook 和 Instagram 带来了挑战。他们采取积极措施试图阻止各种自动化脚本,包括爬取内容的脚本。例如,如果你去 Facebook 网站,那里有一个关于网络爬取的部分,他们谈到了他们为防止网络爬取和网络归档所投入的人力资源。
我们尊重互联网,这些不是我们的材料。作为一个图书馆,我们努力使材料普遍可用。因此,我们也在努力使得 Facebook 和 Instagram 的信息可以被存档,而且我们认为我们完全有权存档公开可访问的信息。
一个令人鼓舞的消息是,格雷厄姆表示,Wayback Machine 正在“积极与几家媒体合作”,以改善进社交媒体内容的存档,希望这件事很快得到改善。
本文最初发表在克雷格·西尔弗曼(Craig Silverman)的新闻信《数字调查》(Digital Investigations)上,全球深度报道网获授权翻译转载
附加资源
识别虚假信息,事实核查专家 Craig Silverman 会用到哪些工具?
 Craig Silverman是ProPublica的记者,负责报道投票、平台、虚假信息和在线操纵。他曾是BuzzFeed News的媒体编辑,在那里他率先报道了数字虚假信息。
Craig Silverman是ProPublica的记者,负责报道投票、平台、虚假信息和在线操纵。他曾是BuzzFeed News的媒体编辑,在那里他率先报道了数字虚假信息。
