
圖:Shutterstock
ProPublica 的克雷格·西爾弗曼(Craig Silverman)在這篇文章中分享了如何批量存檔網頁,比較更改以及查看頁面元素何時被存檔。
在上一期的《數字調查》(Digital Investigations,一份由西爾弗曼運營的新聞信)為如何充分利用 Wayback Machine(網站時光機) 提供了建議。在今天這篇文章中,我又帶來了更多使用 Wayback Machine 的使用技巧,這得益於我對 Wayback Machine 負責人馬克· 格雷厄姆(Mark Graham)的採訪。
他指出了我在上一篇文章中忘記提及的一些功能,以及一個我不知道的功能。我們還討論了存檔社交媒體內容的挑戰。
Wayback Machine 由互聯網檔案館(Internet Archive)運行,這是一個成立 27 年的非營利組織,致力於為所有知識提供普遍訪問。 “我們是一個數字圖書館,”格雷厄姆說。
他說,作為一個圖書館,Wayback Machine 所擁有的是贊助者而不是用戶。讓我們看看 Wayback Machine 中一些對於記者和研究人員最有用的功能。
1. 查看並比較更改
“更改”功能讓你可以比較同一存檔頁面的不同版本,並看到其中的差異。
“可能有一位新聞記者正在寫一篇報道,展示網頁上的內容是如何隨着時間的推移而變化的,”格雷厄姆說,“在這種情況下,他們需要了解 Wayback Machine 的‘更改’(Changes)功能,你可以比較同一 URL 在兩個不同時間點上的內容。”
“更改”功能可以從你在 Wayback Machine 中瀏覽的任何存檔頁面的頂部菜單中訪問:

圖:Wayback Machine 截圖
你也可以直接通過這種URL格式加載它: https://web.archive.org/web/changes/https://www.nytco.com/journalism/
將你想要進行查看的網址放在 https://web.archive.org/web/changes/ 後面,它將顯示一個按年歸檔的網格頁面:
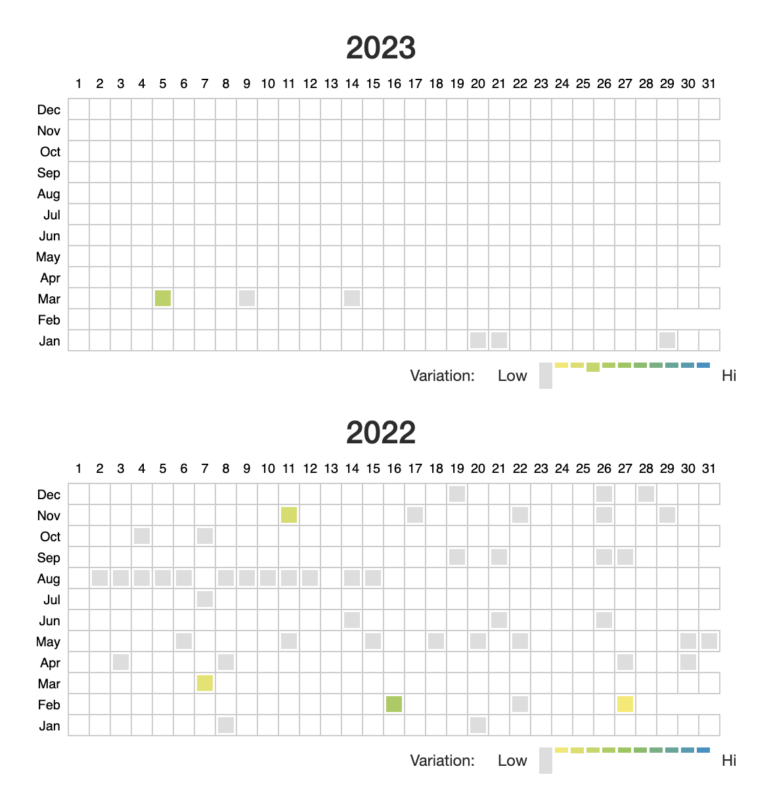
圖:Wayback Machine 截圖
每個陰影方塊都對應一個網頁快照,顏色圖例表示哪些天可能網頁內容出現了重大變化。選擇兩個截圖,然後點擊頁面頂部的“比較”(Compare)按鈕,你就會到到一個並排顯示的網頁快照。
我選擇了2023年3月初的一頁(左)和2022年1月初的一頁(右)。“比較”結果顯示,《紐約時報》關於其新聞業務的頁面更新了底部菜單選項和文本:
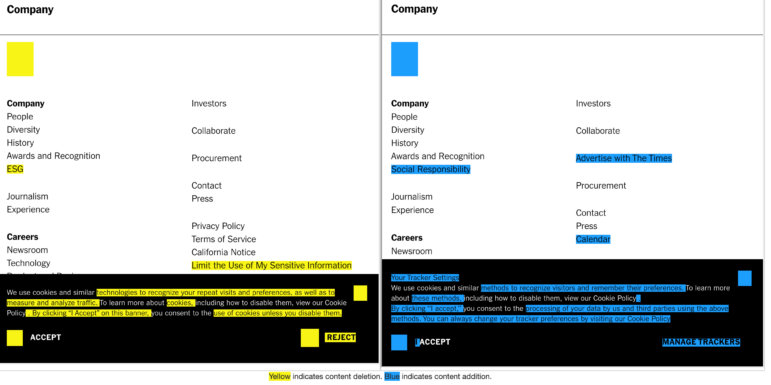
圖:Wayback Machine 截圖
2. 使用“關於此捕獲”來驗證網頁元素
Wayback Machine 的基本功能是捕捉和儲存網頁快照,但實際它的用途更為微妙。
“網絡是混亂的,網絡在不斷變化,”格雷厄姆說。“當我說不斷變化時,指的是它也可以是動態的。”
我問他,我們如何確認網頁快照顯示的正是 Wayback Machine 中列出的日期和時間的頁面內容。簡單的答案是,是,你可以有這個信心。但歸檔頁面的元素可以從不同的歸檔材料中獲取,每個都有自己的時間戳。這就是 Wayback Machine 的微妙之處。
Wayback Machine 有一個功能,可讓您查看網頁上不同元素的時間戳。您可以通過點擊頁面網頁快照右上角的“關於此捕獲”(About this capture)按鈕來訪問它:
Image: Screenshot
以 https://www.nytco.com/journalism/ 為例,我們得到以下結果:
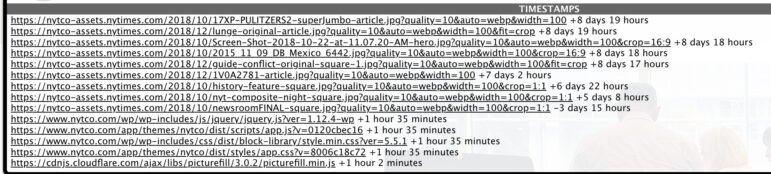
圖:Wayback Machine
儘管該頁面在2021年10月20日被存檔,但 Wayback Machine 會從較新的網頁快照中提取一些元素。上面列出的大部分網頁元素都是靜態圖像,還有幾個 JavaScript 和 CSS 文件。格雷厄姆解釋說,當你在查看一個網頁時,Wayback Machine 會從不同的圖像、JavaScript 和 CSS 文件中提取內容以生成頁面。
“當我們重現一個頁面時,我們實際上是把每個具有自己的URL和自己的存檔的頁面要求收集起來,然後把它們放在一起,”他說。“其中一個挑戰是,這些對象中的每一個可能在不同的時間和日期被存檔。”
“當我們‘回放’一個頁面時,我們實際上會將收集到的每個網頁快照和這個 URL 的實時訪問狀態放到了一起,”他說。“其中的一個挑戰是,每個靜態對象可能會在不同的時間被歸檔。”
例如,網頁頂部的主照片(“17XP-PULITZERS2-superJumbo-article.jpg”)是從我加載歸檔 8 天前抓取的。如果那張照片/文件對你的調查很重要,你可能需要檢查當時的歸檔頁面,看看它是否隨着時間的推移發生了變化,或者尋找一個更接近目標日期的快照。但只要那個文件在每個時間點都保持不變,就沒有問題。
{kind=link}
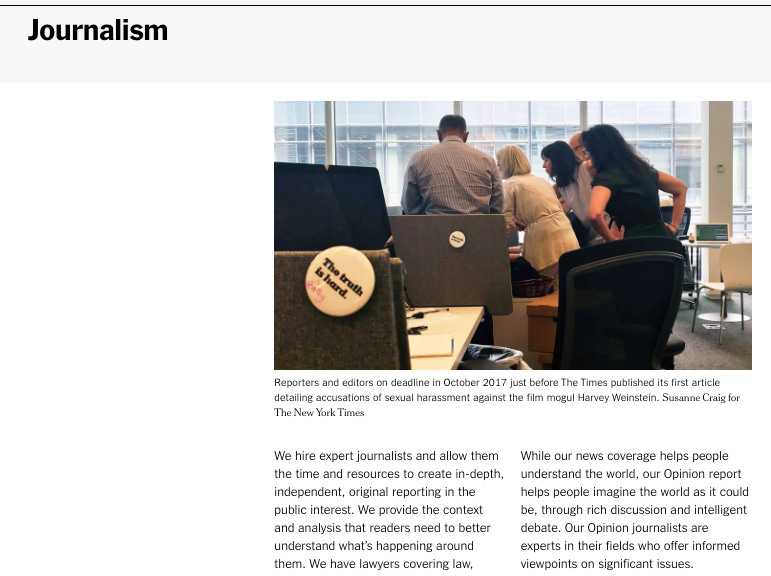
圖:《紐約時報》網站
作為一條普遍但並非絕對的規則,典型網頁的正文通常不會從另一個頁面或文件中提取。因此,它不太可能受到這種動態性的影響。但最安全的做法還是檢查“關於此捕獲”,並確保你引用的頁面捕獲中的文本、圖片或其他元素與你想要查閱的日期一致。
3. 使用 Google 表格對網址進行批量存檔

圖:互聯網檔案館
一旦完成,您將看到下圖,這個時候點擊“歸檔網址”(Archive URLs)。

圖:互聯網檔案館
現在,你可以將 Google 表格的鏈接複製粘貼到相應位置。
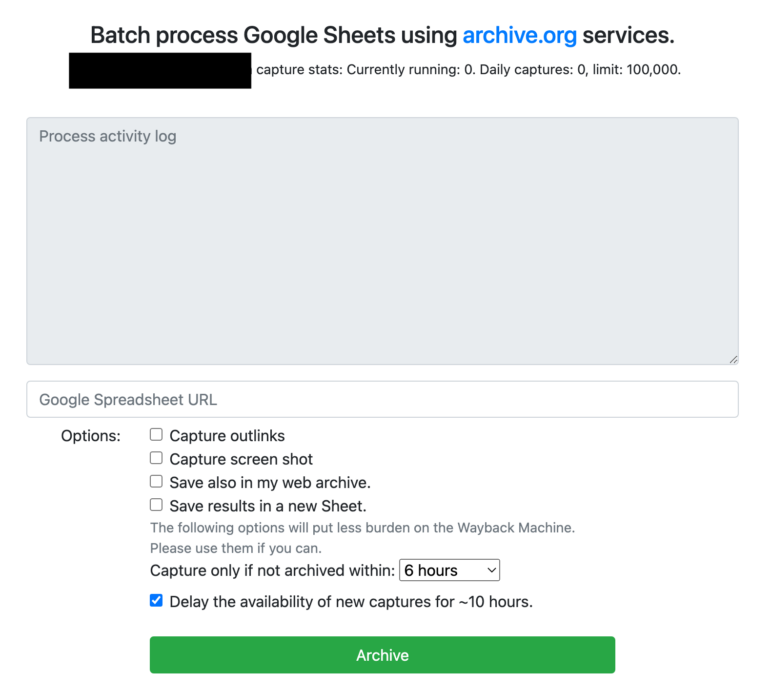
圖:互聯網檔案館
從你將 Google 賬戶和 archive.org 賬戶連接起來後,你所捕捉的所有網頁快照都將存儲在你的 archive.org 賬戶中,方便你查閱。
他說:“這個功能的出現是因為有一天我的妻子問我,‘馬克,我怎樣才能輕鬆地歸檔一堆 URL?’?”
格雷厄姆與互聯網檔案館的工程師們合作,讓 Wayback Machine 實現了這個功能。
4. 發送你的反饋和建議
“由於用戶的要求、提問或建議,如今的 Wayback Machine 有了許多的功能,”格雷厄姆說。“我們非常感謝這些反饋和建議。現在很多功能都是因為用戶的請求才開發的。我們非常歡迎用戶的反饋和建議。”
他鼓勵人們發送郵件到 info@archive.org 進行反饋和建議 。
“我們每天收到數百封電子郵件,我們有一個團隊專門負責查閱和回復這些郵件,”格雷厄姆說。“我個人會回復那些無法由這個團隊直接處理的郵件。”他也特別鼓勵記者們在有問題或請求時主動和他們聯繫。
額外內容:歸檔社交媒體信息
Wayback Machine 的資深用戶會知道,在上面存檔社交媒體內容的難度非常高,這和 Wayback Machine 自身的功能和限制關係不大,而是與像 Meta 這樣的公司阻止內容抓取有關。
這是格雷厄姆關於為什麼很難從社交媒體存檔內容的原因的解釋:
就像一些網站比另一些網站更難存檔一樣,特別是 Facebook 和 Instagram 帶來了挑戰。他們採取積極措施試圖阻止各種自動化腳本,包括爬取內容的腳本。例如,如果你去 Facebook 網站,那裡有一個關於網絡爬取的部分,他們談到了他們為防止網絡爬取和網絡歸檔所投入的人力資源。
我們尊重互聯網,這些不是我們的材料。作為一個圖書館,我們努力使材料普遍可用。因此,我們也在努力使得 Facebook 和 Instagram 的信息可以被存檔,而且我們認為我們完全有權存檔公開可訪問的信息。
一個令人鼓舞的消息是,格雷厄姆表示,Wayback Machine 正在“積極與幾家媒體合作”,以改善進社交媒體內容的存檔,希望這件事很快得到改善。
本文最初發表在克雷格·西爾弗曼(Craig Silverman)的新聞信《數字調查》(Digital Investigations)上,全球深度報道網獲授權翻譯轉載
附加資源
識別虛假信息,事實核查專家 Craig Silverman 會用到哪些工具?
 Craig Silverman是ProPublica的記者,負責報道投票、平台、虛假信息和在線操縱。他曾是BuzzFeed News的媒體編輯,在那裡他率先報道了數字虛假信息。
Craig Silverman是ProPublica的記者,負責報道投票、平台、虛假信息和在線操縱。他曾是BuzzFeed News的媒體編輯,在那裡他率先報道了數字虛假信息。
