图: Shutterstock
这篇文章最初是由 Paul Bradshaw在 Online Journalism Blog上发表,全球深度报道网获授权翻译转载,Bradshaw是伯明翰城市大学数据新闻专业的教师。
我在教授数据新闻时,常常会谈到从数据集中可以挖掘出的故事类型。因此,我选择了100篇数据新闻进行分析,希望能从其中找出每种故事角度的使用频率。
我发现,主要存在七种核心的数据新闻角度。许多故事在讲述时会把其他角度作为次要元素。比如,讲述变化的故事可能会进一步涉及到某个事物的规模,但我研究的所有数据新闻案例,都有一种主导的角度。
在这篇文章中,我会详细解读四种常见的数据新闻角度,看看它们能够如何帮你发现故事创意,执行方式的多样性,以及需要考虑的因素。
角度1:规模
或许,在数据新闻中我们最常见的故事类型就是关于“规模”的故事(scale story),它们揭示了某个大问题,或者热门话题的实际规模。
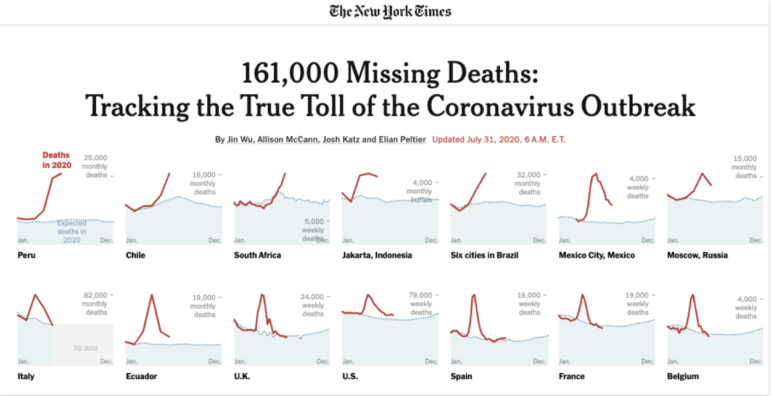
图:纽约时报
最简单的规模故事提供了新数字的更新:可能是最新的失业数字,犯罪量,空气污染,花费在某一区域的金钱,出生,死亡,或者婚姻。
例如,在大流行病的最初几个月,我们每天都有关于病例数量、死亡人数和检测人数等的规模故事。
规模故事的例子包括《研究估计,英国养老院中的冠状病毒死亡人数可能为6000人》,但也包括像《对过于宽松的判决进行审查的制度不充分》这样的故事,其中的主线基于你所识别的问题规模的反应。==
最基础的“规模”故事通常提供一些新的数字更新,可能是最新的失业数据、犯罪数量、空气污染程度、某地区的消费额、出生率、死亡率或婚姻状况。
举个例子,在新冠疫情初期的几个月内,每天都有关于病例数量、死亡人数、检测人数等的“规模”故事。
“规模”故事的典型包括《研究估计,英国养老院的新冠死亡人数可能达到6000人》,其主线是围绕你回应的问题规模来展开的。
有时候,“规模”被用作提供单一事件背景的工具,例如《无人机引发的盖特威克机场混乱》中的“有多少次近错?”或者政策建议如《政府可能禁止新司机在夜间驾驶》中的“有多少新司机不满19岁?”。
“规模”故事是相对较易撰写的类型之一。在很多情况下,你不需要进行复杂的计算。
实际上,主要的工作可能在于为这个“规模”建立上下文。在最糟糕的情况下,“规模”故事只是成了一个“大数字”故事——“花了很多钱”或“很多人受影响”,读者却不清楚这是否真的具有新闻价值,还是仅仅是常态现象。
因此,通过使用百分比或比例(例如,“五分之一”)或比较和类比(“花在该计划上的钱相当于500名教师的工资”)将规模放入上下文中是非常重要的。
你也可能引入变化和/或变异作为次要角度:为你刚刚概述的规模建立历史背景,或者规模如何变化。
例如,在上面的《纽约时报》文章中,新冠病毒爆发的“真实死亡人数”(规模)立即被图表置入了上下文,这些图表显示了自年初以来,在国家不同地区,这个规模是如何改变的。–
因此,把“规模”放入上下文中是非常重要的。你可以使用百分比或比例(如“五分之一”),或者进行比较和类比(如“投入该项目的资金相当于500名教师的工资”)。
你也可以考虑将“变化”和/或“变异”作为次级角度:为你刚刚描述的规模提供历史背景,或者描述规模的变化。
比如,在上述《纽约时报》的文章中,新冠病毒爆发的“真实死亡人数”(即规模)被放入了上下文,图表显示了自年初以来,在英国不同的地区,这个规模是如何变化的。
角度2:变化与静止

图: Belfast Telegraph
关于“变化”的报道与“规模”报道的频次几乎相等,甚至可能更能吸引人们关注。
毕竟,变化本身就是新闻,它为你的标题提供了必要的动词(如“上升”、“暴跌”、“增加”)。
一旦你在数据中发现了某种变化,你可能需要更深入地报告来解答“为什么”的问题。为什么这些数字会上升或下降?
你也可以在你的报道中增加一个次要的视角,去探索这个趋势的变化——在这些数字中,哪些地方上升或下降得最多,哪些地方变动最少。
这能帮你更有针对性地解答“为什么”的问题,因为最可能帮助你了解这个问题的,是那些受影响最大的地方。
季度是指数字中可能受到的季度影响,这些影响通常是可以预测和正常的,因此不具备新闻性。比如财政年度或学期的结束、新车的发布或简单的温度变化等,通常我们会通过与去年同期相比(比如,比较今年8月和去年8月的数据)或进行季度调整来避免这种影响。
误差范围,则是指相关数字和真实数值可能存在误差的范围。因为许多数据集都是基于样本,然后将结果推广到整个观察人口,误差范围(或置信区间)被用来表示这种准确性的误差。如果所观察到的任何变化都在这个误差范围内,那其实并不能断言有任何实质性的改变。
“变化”故事的一个变种是“无变化”的角度。例如,这篇关于公司破产的报道,本来期待看到变化,但发现在疫情期间,并未出现公司破产数量的增加,于是就寻求专家对这一反直觉发现进行评论。
角度3:排名
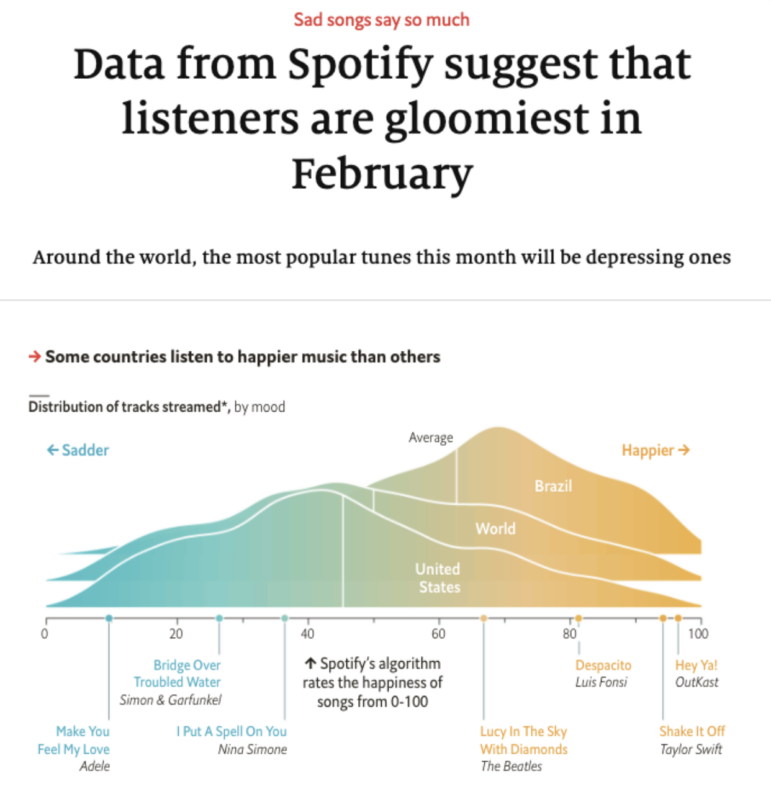
这篇《经济学人》的文章是一个“排名”类的报道,因为它显示了人们感到最抑郁的月份。图:《经济学人》报道截图
“排名”类的故事主要关注谁或哪个事物在数据集中表现最好或最差,或者特定的关注对象(如当地警察局、学校或团体,或者对于专业媒体来说,可能是某个行业)与其他对象的相对位置。
这一类别的典型报道可能包括“我们的地区是犯罪率最高的地区之一”或“我们的学生在全国考试中排名第三”。
你可能会关注受影响最严重的地方,比如在报道“伯明翰的部分地区属于受通用信用预付款影响最严重的英国十大地区中”时,或者你可能会比较你的行业与其他行业的表现,就像在报道“建筑业是英国第三危险的行业”时那样。
然而,“排名”类故事也可以揭示数据集中最好或最差的时间、地点或类别。
前面提到的《经济学人》的文章,例如,讲的人们喜欢在哪个月最喜欢听忧郁的歌曲。另一方面,报道伯明翰生活的文章,主要介绍了桑德韦尔犯罪率最高的类型,以及你最有可能成为受害者的地点。
另外,《经济学人》在其数据新闻专栏中,专门介绍了“如何编制指数”。
那些指数到底有多实用呢?任何非基于客观标准的排名都可能会遭到批评。定性排名是基于主观度量标准的。比如,对于某些人来说,‘可以忍受’和‘不舒服’可能几乎没有区别,但‘无法忍受’可能比‘不希望’的感受要糟糕两倍?在顺序量表上,这些度量之间的距离是主观的,但为了进行排名,我们必须为它们赋予一个数值得分。
自1986年以来,《经济学人》一直在发布它的‘巨无霸指数’,这是一种衡量货币价值的方式。在2011年,我们发布了‘掷鞋指数’,用于评估阿拉伯世界发生动荡的可能。而今年,我们推出了‘全球正常性指数’,用于追踪各国从新冠疫情中恢复的程度。一个不完美的衡量方式总比完全没有比较的方法要好。
排名类型的新闻在处理上下文时需要格外谨慎:比如,一个地区的犯罪、疾病或污染情况可能最严重,但这可能仅仅是因为它的人口最多。报道的日期也可能会扭曲数据:就像FullFact 所指出的那样,新冠病例数经常在周二达到峰值,因为这个数据“包含了许多在周末没有报告的病例”。
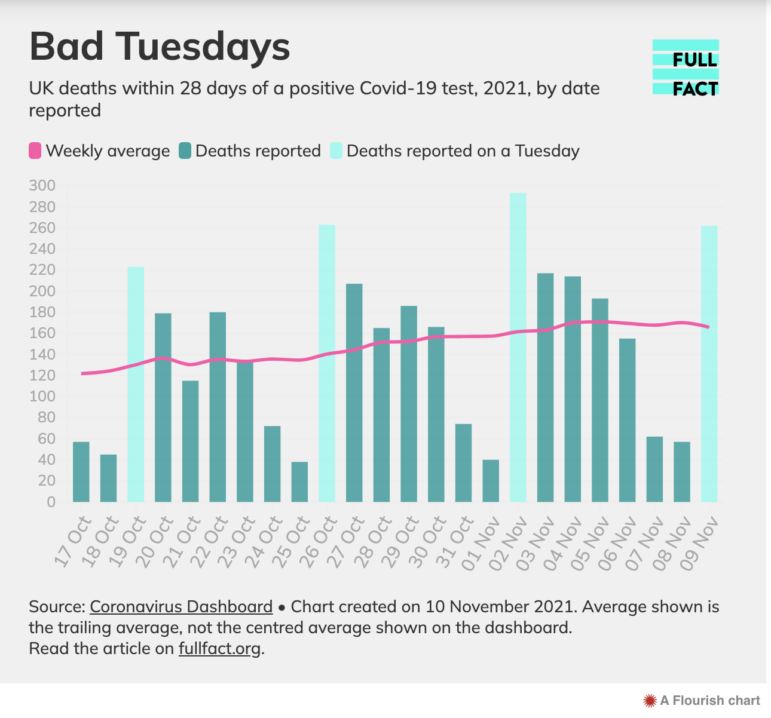
角度4:差异
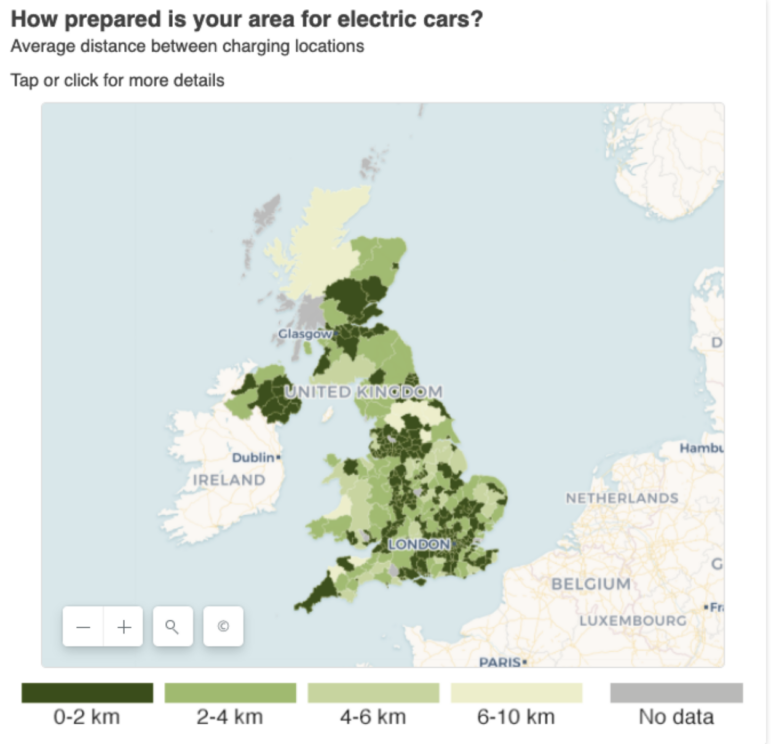
这篇由 Aimee Stanton 撰写的 BBC 共享数据的报道,关注的是英国不同地区电动汽车充电桩的可达性的差异。图:BBC
当我们在寻求平等对待或试图反映生活的某一部分时,差异性的报道效果尤其显著。
经典的方法包括使用等值线图或热力图,这些图表展示了一个国家中某些地区对某物的获取能力或对某物的需求量。
例如,BBC 的这篇报道,就揭示了你在英格兰的居住地可能会决定你是否能接受生育治疗。
差异性的故事可能揭示不公平的存在,或当人们已经意识到这个问题,那么这类故事就能清楚地指出这种不公平是如何以及在哪里发生的。
类似于 ProPublica 的“机器偏见(Machine Bias)”系列的算法问责故事,通常都关注差异以及对算法解构后揭示出的不公平:这可能体现在人们受到的判决方式不同,或者得到的保险报价不同,尽管在关键方面他们之间并没有实质性差异。
差异性故事也可以用来突出服务不足的需求区域,或者供应短缺的地方:例如,我曾为 BBC 共享数据栏目做过一个关于电动汽车充电站的故事,研究的内容包括确定国家中的基础设施数量和它们的分布情况。数据所描绘的情况为案例研究和反馈提供了基础。
 Paul Bradshaw 在英国伯明翰城市大学负责数据新闻硕士和多平台与移动新闻硕士项目,他同时还在 BBC 担任数据顾问记者。
Paul Bradshaw 在英国伯明翰城市大学负责数据新闻硕士和多平台与移动新闻硕士项目,他同时还在 BBC 担任数据顾问记者。
