圖: Shutterstock
這篇文章最初是由 Paul Bradshaw在 Online Journalism Blog上發表,全球深度報道網獲授權翻譯轉載,Bradshaw是伯明翰城市大學數據新聞專業的教師。
我在教授數據新聞時,常常會談到從數據集中可以挖掘出的故事類型。因此,我選擇了100篇數據新聞進行分析,希望能從其中找出每種故事角度的使用頻率。
我發現,主要存在七種核心的數據新聞角度。許多故事在講述時會把其他角度作為次要元素。比如,講述變化的故事可能會進一步涉及到某個事物的規模,但我研究的所有數據新聞案例,都有一種主導的角度。
在這篇文章中,我會詳細解讀四種常見的數據新聞角度,看看它們能夠如何幫你發現故事創意,執行方式的多樣性,以及需要考慮的因素。
角度1:規模
或許,在數據新聞中我們最常見的故事類型就是關於“規模”的故事(scale story),它們揭示了某個大問題,或者熱門話題的實際規模。
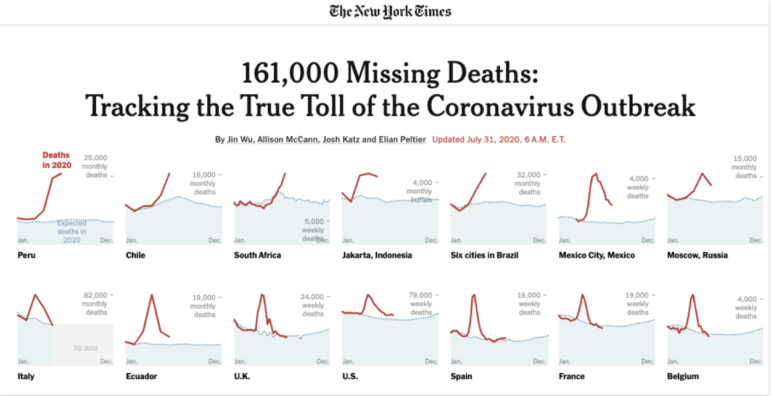
圖:紐約時報
最簡單的規模故事提供了新數字的更新:可能是最新的失業數字,犯罪量,空氣污染,花費在某一區域的金錢,出生,死亡,或者婚姻。
例如,在大流行病的最初幾個月,我們每天都有關於病例數量、死亡人數和檢測人數等的規模故事。
規模故事的例子包括《研究估計,英國養老院中的冠狀病毒死亡人數可能為6000人》,但也包括像《對過於寬鬆的判決進行審查的制度不充分》這樣的故事,其中的主線基於你所識別的問題規模的反應。==
最基礎的“規模”故事通常提供一些新的數字更新,可能是最新的失業數據、犯罪數量、空氣污染程度、某地區的消費額、出生率、死亡率或婚姻狀況。
舉個例子,在新冠疫情初期的幾個月內,每天都有關於病例數量、死亡人數、檢測人數等的“規模”故事。
“規模”故事的典型包括《研究估計,英國養老院的新冠死亡人數可能達到6000人》,其主線是圍繞你回應的問題規模來展開的。
有時候,“規模”被用作提供單一事件背景的工具,例如《無人機引發的蓋特威克機場混亂》中的“有多少次近錯?”或者政策建議如《政府可能禁止新司機在夜間駕駛》中的“有多少新司機不滿19歲?”。
“規模”故事是相對較易撰寫的類型之一。在很多情況下,你不需要進行複雜的計算。
實際上,主要的工作可能在於為這個“規模”建立上下文。在最糟糕的情況下,“規模”故事只是成了一個“大數字”故事——“花了很多錢”或“很多人受影響”,讀者卻不清楚這是否真的具有新聞價值,還是僅僅是常態現象。
因此,通過使用百分比或比例(例如,“五分之一”)或比較和類比(“花在該計划上的錢相當於500名教師的工資”)將規模放入上下文中是非常重要的。
你也可能引入變化和/或變異作為次要角度:為你剛剛概述的規模建立歷史背景,或者規模如何變化。
例如,在上面的《紐約時報》文章中,新冠病毒爆發的“真實死亡人數”(規模)立即被圖表置入了上下文,這些圖表顯示了自年初以來,在國家不同地區,這個規模是如何改變的。–
因此,把“規模”放入上下文中是非常重要的。你可以使用百分比或比例(如“五分之一”),或者進行比較和類比(如“投入該項目的資金相當於500名教師的工資”)。
你也可以考慮將“變化”和/或“變異”作為次級角度:為你剛剛描述的規模提供歷史背景,或者描述規模的變化。
比如,在上述《紐約時報》的文章中,新冠病毒爆發的“真實死亡人數”(即規模)被放入了上下文,圖表顯示了自年初以來,在英國不同的地區,這個規模是如何變化的。
角度2:變化與靜止

圖: Belfast Telegraph
關於“變化”的報道與“規模”報道的頻次幾乎相等,甚至可能更能吸引人們關注。
畢竟,變化本身就是新聞,它為你的標題提供了必要的動詞(如“上升”、“暴跌”、“增加”)。
一旦你在數據中發現了某種變化,你可能需要更深入地報告來解答“為什麼”的問題。為什麼這些數字會上升或下降?
你也可以在你的報道中增加一個次要的視角,去探索這個趨勢的變化——在這些數字中,哪些地方上升或下降得最多,哪些地方變動最少。
這能幫你更有針對性地解答“為什麼”的問題,因為最可能幫助你了解這個問題的,是那些受影響最大的地方。
季度是指數字中可能受到的季度影響,這些影響通常是可以預測和正常的,因此不具備新聞性。比如財政年度或學期的結束、新車的發布或簡單的溫度變化等,通常我們會通過與去年同期相比(比如,比較今年8月和去年8月的數據)或進行季度調整來避免這種影響。
誤差範圍,則是指相關數字和真實數值可能存在誤差的範圍。因為許多數據集都是基於樣本,然後將結果推廣到整個觀察人口,誤差範圍(或置信區間)被用來表示這種準確性的誤差。如果所觀察到的任何變化都在這個誤差範圍內,那其實並不能斷言有任何實質性的改變。
“變化”故事的一個變種是“無變化”的角度。例如,這篇關於公司破產的報道,本來期待看到變化,但發現在疫情期間,並未出現公司破產數量的增加,於是就尋求專家對這一反直覺發現進行評論。
角度3:排名
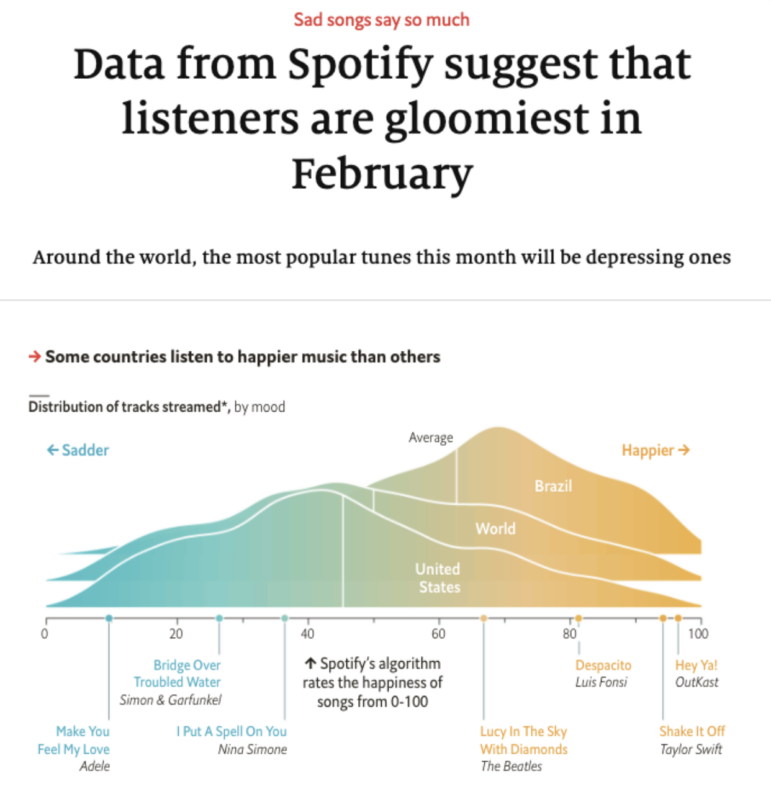
這篇《經濟學人》的文章是一個“排名”類的報道,因為它顯示了人們感到最抑鬱的月份。圖:《經濟學人》報道截圖
“排名”類的故事主要關注誰或哪個事物在數據集中表現最好或最差,或者特定的關注對象(如當地警察局、學校或團體,或者對於專業媒體來說,可能是某個行業)與其他對象的相對位置。
這一類別的典型報道可能包括“我們的地區是犯罪率最高的地區之一”或“我們的學生在全國考試中排名第三”。
你可能會關注受影響最嚴重的地方,比如在報道“伯明翰的部分地區屬於受通用信用預付款影響最嚴重的英國十大地區中”時,或者你可能會比較你的行業與其他行業的表現,就像在報道“建築業是英國第三危險的行業”時那樣。
然而,“排名”類故事也可以揭示數據集中最好或最差的時間、地點或類別。
前面提到的《經濟學人》的文章,例如,講的人們喜歡在哪個月最喜歡聽憂鬱的歌曲。另一方面,報道伯明翰生活的文章,主要介紹了桑德韋爾犯罪率最高的類型,以及你最有可能成為受害者的地點。
另外,《經濟學人》在其數據新聞專欄中,專門介紹了“如何編製指數”。
那些指數到底有多實用呢?任何非基於客觀標準的排名都可能會遭到批評。定性排名是基於主觀度量標準的。比如,對於某些人來說,‘可以忍受’和‘不舒服’可能幾乎沒有區別,但‘無法忍受’可能比‘不希望’的感受要糟糕兩倍?在順序量表上,這些度量之間的距離是主觀的,但為了進行排名,我們必須為它們賦予一個數值得分。
自1986年以來,《經濟學人》一直在發布它的‘巨無霸指數’,這是一種衡量貨幣價值的方式。在2011年,我們發布了‘擲鞋指數’,用於評估阿拉伯世界發生動蕩的可能。而今年,我們推出了‘全球正常性指數’,用於追蹤各國從新冠疫情中恢復的程度。一個不完美的衡量方式總比完全沒有比較的方法要好。
排名類型的新聞在處理上下文時需要格外謹慎:比如,一個地區的犯罪、疾病或污染情況可能最嚴重,但這可能僅僅是因為它的人口最多。報道的日期也可能會扭曲數據:就像FullFact 所指出的那樣,新冠病例數經常在周二達到峰值,因為這個數據“包含了許多在周末沒有報告的病例”。
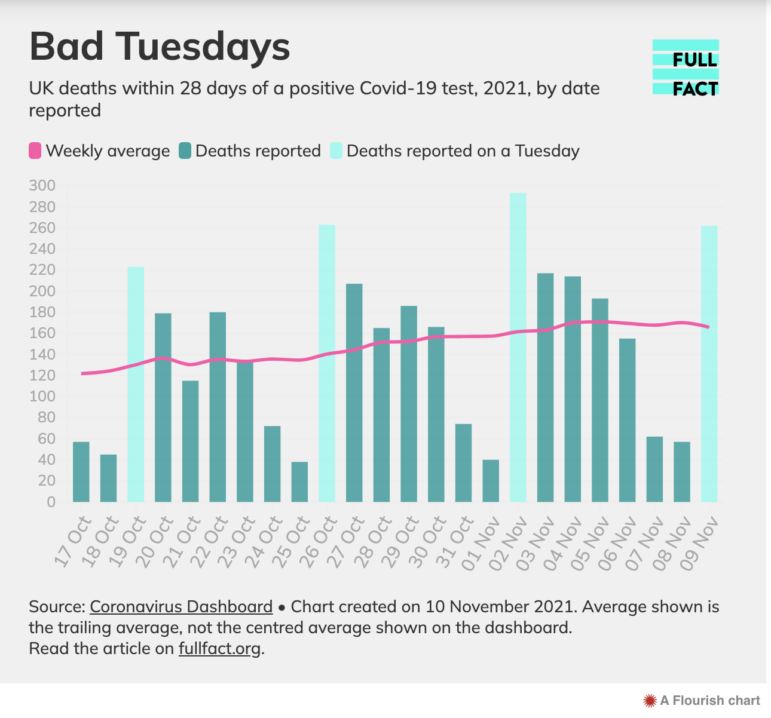
角度4:差異
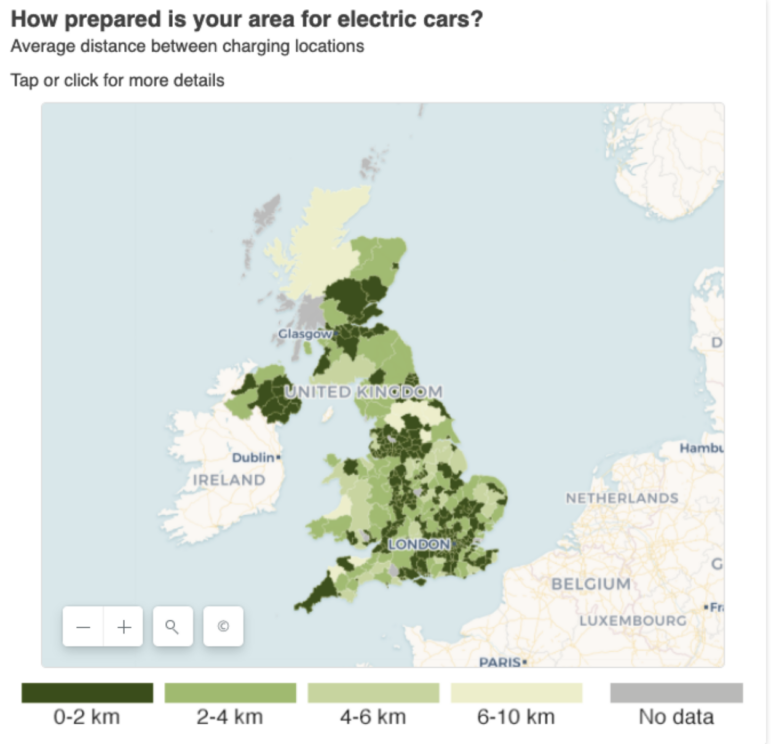
這篇由 Aimee Stanton 撰寫的 BBC 共享數據的報道,關注的是英國不同地區電動汽車充電樁的可達性的差異。圖:BBC
當我們在尋求平等對待或試圖反映生活的某一部分時,差異性的報道效果尤其顯著。
經典的方法包括使用等值線圖或熱力圖,這些圖表展示了一個國家中某些地區對某物的獲取能力或對某物的需求量。
例如,BBC 的這篇報道,就揭示了你在英格蘭的居住地可能會決定你是否能接受生育治療。
差異性的故事可能揭示不公平的存在,或當人們已經意識到這個問題,那麼這類故事就能清楚地指出這種不公平是如何以及在哪裡發生的。
類似於 ProPublica 的“機器偏見(Machine Bias)”系列的算法問責故事,通常都關注差異以及對算法解構後揭示出的不公平:這可能體現在人們受到的判決方式不同,或者得到的保險報價不同,儘管在關鍵方面他們之間並沒有實質性差異。
差異性故事也可以用來突出服務不足的需求區域,或者供應短缺的地方:例如,我曾為 BBC 共享數據欄目做過一個關於電動汽車充電站的故事,研究的內容包括確定國家中的基礎設施數量和它們的分布情況。數據所描繪的情況為案例研究和反饋提供了基礎。
 Paul Bradshaw 在英國伯明翰城市大學負責數據新聞碩士和多平台與移動新聞碩士項目,他同時還在 BBC 擔任數據顧問記者。
Paul Bradshaw 在英國伯明翰城市大學負責數據新聞碩士和多平台與移動新聞碩士項目,他同時還在 BBC 擔任數據顧問記者。
